2022 ADsP 데이터분석준전문가 개념 정리 및 요약
2022 ADsP 데이터분석준전문가 개념 정리 및 요약
★ : 객관식 기출 / ☆ : 단답형 기출 / ADsP 최신 기출(32회) 반영
1과목 - 데이터 이해
#데이터의 유형
(1) 정성적(qualitative) 데이터
- 형태와 형식이 정해져있지않아 저장/검색/분석하는데 많은 비용과 기술적 투자가 수반된다.
예) 언어, 문자, 기상특보(상태) 등
(2) 정량적(quantitative) 데이터
- 데이터의 양이 크게 증가하더라도 저장, 검색, 분석하여 활용하기 용이하다.
예) 수치, 도형, 기호 등
#지식경영의 핵심 이슈
- 데이터는 지식경영의 핵심 이슈인 암묵지와 형식지의 상호작용에 중요한 역할을 한다.
구분 | 의미 | 예 |
암묵지 | 학습과 경험을 통해 개인에게 체화되어있지만 겉으로 드러나지 않는 지식 | 김치 담그기, 자전거타기 |
형식지 | 문서나 매뉴얼처럼 형상화된 지식 | 교과서, 비디오, DB |
1. 암묵지
- 사회적으로 중요하지만 다른 사람에게 공유되기 어렵다.
- 개인에게 축적된 내면화된 지식이 조직의 지식으로 공동화 된다.
2. 형식지
- 전달과 공유가 용이하다.
- 언어, 기호, 숫자로 표준화된 지식이 개인의 지식으로 연결화 된다.
#SECI모델
(Socialization – Externalization - Combination - Internalization Model) ★
- 암묵지+형식지의 4단계 지식전환 모드
1) 공동화 : 경험을 공유를 통해 새로운 암묵지 창조
- 암묵지 지식 노하우를 다른 사람에게 알려주기
2) 표출화 : 암묵지에서 구체적인 개념을 도출하여, 암묵지를 형식지로 표출
- 암묵적 지식 노하우를 책이나 교본 등 형식지로 만들기
3) 연결화 : 표출된 형식지의 완성도를 높여 지식체계로 전환
- 책이나 교본(형식지)에 자신이 알고 있는 새로운 지식(형식지)을 추가하기
4) 내면화 : 표준화와 연결화로 공유된 정신 모델이나 기술적 노하우가 개인의 암묵지로 변환
- 만들어진 책이나 교본(형식지)를 보고 다른 직원들이 암묵적 지식(노하우)을 습득
5) 위의 4가지 과정 (공동화, 표출화, 연결화, 내면화)이 순환하면서 창조됨
#DIKW 피라미드

#데이터(자료) 양의 단위
구분 | 의미 | 예 |
지혜 | - 지식의 축적과 아이디어가 결합된 창의적인 산물 - 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 창의적인 아이디어 | A마트의 다른 상품들도 B마트보다 더 쌀 것이라고 판단한다. |
지식 ★ | - 데이터를 통해 도출된 다양한 정보를 구조화하여 유의미한 정보를 분류하고 개인적인 경험을 결합시켜 고유의 지식으로 내재화된 것 - 상호 연결된 정보 패턴을 이해하여 이를 토대로 예측한 결과 | 상대적으로 저렴한 A마트에서 연필을 사야겠다. |
정보 ★ | - 데이터의 가공, 처리와 데이터 간 연관관계 속에서 의미가 도출된 것 - 데이터의 가공 및 상관관계 간 이해를 통해 패턴을 인식하고 그 의미를 부여한 데이터 | A마트의 연필이 더 싸다. |
데이터 ★ | - 개별 데이터 자체로는 의미가 중요하지 않은 객관적인 사실 - 존재형식을 불문하고, 타 데이터와의 상관관계가 없는 가공하기 전의 순수한 수치나 기호 | A는 100원, B는 200원에 연필을 판매 |
- 일반적으로 8개의 비트를 하나로 묶어 1 Byte라 하고 있으며, 1 Byte가 표현할 수 있는 정보의 개수는 2의 8제곱 = 256개가 된다. 바이트는 256종류의 정보를 나타낼 수 있어 숫자, 영문자, 특수문자 등을 모두 표현할 수 있다. ★
#데이터(자료) 양의 단위 ★
- b < B < KB < MB < GB < TB < PB < EB < ZB < YB
#데이터베이스의 특징 ★
(1) 통합된 데이터(integrated data)
- 동일한 내용의 데이터가 중복되어 있지 않다는 것을 의미.
- 데이터 중복은 관리상의 복잡한 부작용을 초래
(2) 저장된 데이터(stored data)
- 자기 디스크나 자기 테이프 등과 같이 컴퓨터가 접근할 수 있는 저장 매체에 저장되는 것.
- 데이터베이스는 기본적으로 컴퓨터 기술을 바탕으로 한 것
(3) 공용 데이터(shared data)
- 여러 사용자가 서로 다른 목적으로 데이터를 공동으로 이용한다는 것을 의미.
- 대용량화 되고 구조가 복잡하다.
(4) 변화되는 데이터(changeable data)
- 데이터베이스에 저장된 내용은 곧 데이터베이스의 현 상태를 나타냄.
- 다만 이 상태는 새로운 데이터의 삽입, 기존 데이터의 삭제, 갱신으로 항상 변화하면서도 현재의 정확한 데이터를 유지해야 함
#데이터베이스의 설계 절차 ★
- 요구사항 분석 > 개념적 설계 > 논리적 설계 > 물리적 설계
#OLTP (On-Line Transaction Processing) ★
- 호스트 컴퓨터와 온라인으로 접속된 여러 단말 간의 처리 형태의 하나이다. 여러 단말에서 보내온 메시지에 따라 호스트 컴퓨터가 데이터베이스를 액세스하고 바로 처리 결과를 돌려보내는 형태를 말한다. 데이터베이스의 데이터를 수시로 갱신하는 프로세싱을 의미한다.
예) 주문 입력 시스템, 재고 관리 시스템 등
#OLAP (On-Line Analytical Processing)
- 정보 위주의 분석 처리를 의미하며, 다양한 비즈니스 관점에서 쉽고 빠르게 다차원적인 데이터에 접근하여 의사 결정에 활용할 수 있는 정보를 얻게 해주는 시스템.
#CRM (Customer Relationship Management) ★
- 기업 내부 데이터베이스를 기반으로 고객과 관련된 내·외부 자료를 분석·통합해 고객 중심 자원을 극대화하고 이를 토대로 고객 특성에 맞게 마케팅 활동을 계획·지원·평가하는 과정.
#SCM (Supply Chain Management) ★☆
- 기업에서 원재료의 생산·유통 등 모든 공급망 단계를 최적화해 수요자가 원하는 제품을 원하는 시간과 장소에 제공하는 "공급망 관리"
#ERP (Enterprise Resource Planning) ★
- 인사·재무·생산 등 기업의 전 부문에 걸쳐 독립적으로 운영되던 각종 관리시스템의 경영자원을 하나의 통합 시스템으로 재구축함으로써 생산성을 극대화하려는 경영혁신기법
#KMS (Knowledge Management System) ★
- 조직 내 구성원이 축적하고 있는 노하우 등 암묵적 지식을 형식지로 표출화 될 수 있도록 지원하는 등, 조직의 경쟁력 향상을 위해 지식 자원을 체계화 하고 원활하게 공유 될 수 있도록 지원하는 시스템
#NEIS ★
- 사회기반구조로써의 데이터베이스
#BI (Business Intelligence) ★
- 데이터 기반 의사결정을 지원하기 위한 리포트 중심의 도구
- 기업이 보유하고 있는 소많은 데이터를 정리하고 분석해 기업의 의사결정에 활용하는 일련의 프로세스를 말한다. 즉, 기업의 사용자가 더 좋은 의사결정을 하도록 데이터 수집, 저장, 분석, 접근을 지원하는 응용시스템과 기술
- 데이터를 통합/분석하여 기업 활동에 연관된 의사결정을 돕는 프로세스
- 가트너의 정의 : ‘여러 곳에 산재되어 있는 데이터를 수집하여 체계적이고 일목요연하게 정리함으로써 사용자가 필요로 하는 정보를 정확한 시간에 제공할 수 있는 환경’
#BI와 비교하여 빅데이터 분석에 대한 키워드★
- Information, Ad hoc Report, Alerts, Clean Data
#BA (Business Intelligence) ★
- 데이터와 통계를 기반으로 성과에 대한 이해와 비즈니스 통찰력에 초점을 준 분석 방법
- 경영 의사결정을 위한 통계적이고 수학적인 분석에 초점을 둔 기법
- BI 보다 진보된 형태
#메타데이터 ★
- 데이터에 관한 구조화된 데이터로, 다른 데이터를 설명해주는 데이터.
#인덱스 ★
- 데이터베이스 내의 데이터를 신속하게 정렬하고 탐색하게 해주는 구조.
- 원하는 형태의 배열과 찾아보기를 가능하게 해주는 기능.
#빅데이터의 정의
(1) 3V
- Volume (양): 데이터의 규모 측면
- Variety (다양성): 데이터의 유형과 소스 측면
- Velocity (속도): 데이터의 수집과 처리 측면
(2) 데이터 자체 뿐 아니라 처리, 분석 기술적 변화까지 포함되는 중간 범위의 정의
- 새로운 처리, 저장, 분석 기술 및 아키텍처
- 클라우드 컴퓨팅 활용 : 빅데이터 처리 비용 감소 ★
⇒ 빅데이터 분석에 경제성을 제공 / 예) 하둡
(3) 인재, 조직 변화까지 포함해 넓은 관점에서의 정의
(4) 그 밖의 정의
- 일반적인 데이터베이스 소프트웨어로 저장, 관리, 분석할 수 있는 범위를 초과하는 규모의 데이터 ★
- 다양한 종류의 대규모 데이터로부터 저렴한 비용으로 가치를 추출하고 데이터의 초고속 수집, 발굴, 분석을 지원하도록 고안된 차세대 기술 및 아키텍처 ★
#빅데이터의 출현배경 ★
- 빅데이터는 없었던 것이 새로 등장한 것이 아니라 기존의 데이터, 처리방식, 다루는 사람과 조직 차원에서 일어나는 "변화"를 말한다.
예) 트위터, 페이스북 등 SNS의 급격한 확산 ★
#데이터의 가치 측정이 어려운 이유 ★☆
- 데이터 재사용이 일반화되면서 특정 데이터를 언제 누가 사용했는지 알기 힘들기 때문
- 빅데이터는 기존에 존재하지 않던 가치를 창출하기 때문
- 분석 기술의 발전으로 과거 분석이 불가능했던 데이터를 분석할 수 있게 되었기 때문
#빅데이터에 거는 기대
산업혁명의 석탄, 철 | 제조업 뿐 아니라 서비스 분야의 생산성을 획기적으로 끌어올려 사회/경제/문화 전반에 혁명적 변화를 가져올 것으로 기대 |
21세기 원유 | 경제 성장에 필요한 정보를 제공함으로써 생산성을 한 단계 향상시키고 기존에 없던 새로운 범주의 산업을 만들어 낼 것으로 전망 |
렌즈 | 렌즈를 통해 현미경이 생물학에 미쳤던 영향만큼 데이터가 산업 발전에 영향을 미칠 것 |
플랫폼 ★ | 다양한 서드파티 비즈니스에 활용되면서 플랫폼 역할을 할 것으로 전망 ex) kakao, facebook |
#빅데이터의 상호관계 ★☆
사물 인터넷(사물끼리 정보를 주고받는 기능) ☆ ㅡ Datafication(데이터화) ★
#빅데이터가 만들어 내는 본질적인 변화 ★
(1) 사전처리에서 사후처리로
- 필요한 정보만 수집하고 필요하지 않은 정보는 버리는 시스템에서 가능한 한 많은 데이터를 모으고 그 데이터를 다양한 방식으로 조합해 숨은 정보를 찾아낸다.
(2) 표본조사에서 전수조사로 ★
- 표본을 조사하는 기존의 지식 발견 방식이 데이터 수집 비용의 감소와 클라우드 컴퓨팅 기술의 발전으로 인해 전수조사로 변화하게 된다. 이에 따라 샘플링이 주지 못하는 패턴이나 정보를 찾을 수 있게 된다.
(3) 질보다 양으로
- 데이터가 지속적으로 추가될 때 양질의 정보가 오류보다 많아져 전체적으로 좋은 결과 산출에 긍정적인 영향을 미친다는 추론에 바탕을 두고 변화
예) 구글의 자동 번역 시스템 (Volume) ★
(4) 인과관계에서 상관관계로
- 상관관계를 통해 특정 현상의 발생 가능성이 포착되고, 그에 상응하는 행동을 하도록 추천되는 일이 점점 늘어나 데이터 기반의 상관관계 분석이 주는 인사이트가 인과관계에 의해 미래 예측을 점점 더 압도해 가는 시대가 도래하게 될 것으로 전망된다.
#빅데이터 활용 3요소 ★
데이터 | 모든 것의 데이터화 |
기술 | 진화하는 알고리즘, 인공지능 |
인력 | 데이터 사이언티스트, 알고리즈미스트 |
#산업별 분석 애플리케이션
산업 | 일차원적 분석 애플리케이션 |
금융 서비스 | 신용점수 산정, 사기 탐지, 가격 책정, 프로그램 트레이딩, 클레임 분석, 고객 수익성 분석 |
소매업 | 판촉, 매대 관리, 수요 예측, 재고 보충, 가격 및 제조 최적화 |
제조업 | 공급사슬 최적화, 수요예측, 재고 보충, 보증서 분석, 맞춤형 상품 개발 |
에너지 ★ | 트레이딩, 공급/수요 예층 |
온라인 | 웹 매트릭스, 사이트 설계, 고객 추천 |
#데이터의 유형 ★
유형 | 내용 | 예시 |
정형 데이터 | - 형태가 있으며 연산 가능 - 주로 관계형 데이터베이스에 저장됨 - 데이터 자체 분석 가능 | 관계형 데이터베이스, ERP, CRM, SCM, 물류 창고 재고 데이터, csv, 스프레드시트, Transaction data, Demand Forecast ★ |
반정형 데이터 | - 형태(스키마, 메타데이터)가 있으며 연산이 불가능 - 주로 파일로 저장됨 ★ - 보통 API 형태로 제공되기 때문에 데이터 처리기술(파싱)이 요구됨 - 데이터 분석은 가능, 해석 불가 - 메타데이터를 활용하여 해석해야 함 | XML, HTML, JSON, report, blogs and news, social media, Competitor Pricing ★, 기기에서 생성된 데이터, 모바일데이터, 로그데이터, 센서데이터, 메타데이터, 스키마 |
비정형 데이터 | - 형태가 없으며 연산이 불가능 - 주로 NoSQL에 저장됨 - 데이터 자체 분석 불가 | 소셜데이터, 이미지, machine data, E-mail Records ★, E-mail 전송 데이터, 페이스북 소셜 데이터 검색어, 음성, 영상, 문자(word, pdf) |
#데이터웨어하우스 ★
- 기업 내의 의사결정지원 어플리케이션을 위한 정보 기반을 제공하는 하나의 통합된 데이터 저장 공간
- ETL*은 주기적으로 내부 및 외부 데이터베이스로부터 정보를 추출하고 정해진 규약에 따라 정보를 변환한 후에 데이터웨어하우스에 정보를 적재한다.
- 데이터 웨어하우스의 4가지 특징 – 주제지향성, 통합성, 비휘발성, 시계열성**
*ETL(Extraction, Transformation and Load) ★
- Extraction: 데이터 원청 소스에서 데이터 획득
- Transformation: 데이터 클렌징, 형식변환, 표준화, 통합
- Load: 특정 목표 시스템에 적재
**데이터웨어하우스의 시계열성 ★
- 데이터웨어하우스에서 관리하는 데이터들은 수시적인 갱신이나 변경이 발생할 수 없다.
#데이터 마트 ★☆
- 재무, 생상, 운영 등과 같이 특정 조직의 특정 업무 분야에 초점을 맞춰 구축
#플랫폼형 비즈니스 모델 ★
- 상품, 서비스, 기술 등의 기반 위에 다른 이해관계자들이 보완적인 상품, 서비스, 기술을 제공하는 생태계 구축을 목표로 하는 비즈니스 모델
- 협의의 분석 플랫폼 : 데이터 처리 프레임 워크 ★
#비즈니스 모델 캔버스(Business Model Canvas) ★

- 비즈니스 모델을 일목묘연하게 보여주는 그래픽 템플릿
- 9개로 구성된 중요한 비즈니스 영역/블록들의 유기적인 연결을 통해 기업이 가치를 창출하고 전달하고 획득하는 원리를 9가지 요소로 분석
① Customer Segments(고객 세그먼트)
② Value Propositions(가치 제안)
③ Channel(채널) ★
- 고객과 기업의 의사소통 방법
- 기업이 고객니즈를 충족시키기 위해 가치를 전달할 방법
- 고객 세그먼트에 따라 어떤 채널을 통해 가치를 전달할 것인지, 어떤 채널을 사용해야 고객에게 효과적으로 가치를 전달하고 기업 입장에서는 수익을 극대화할 수 있는지에 대한 부분
④ Customer Relationships(고객 관리)
⑤ Key Resources(핵심 자원)
⑥ Revenue Streams(수익원)
⑦ Key Activities(핵심활동)
⑧ Key Partnerships(핵심 파트너)
⑨ Cost Structure(비용 구조)
#빅데이터 활용 기본 테크닉 ★
테크닉 | 내용 |
연관규칙학습 | - 변인들 간에 주목할 만한 상관관계가 있는지 찾아내는 방법 |
예) 커피를 구매하는 사람이 탄산음료를 더 많이 사는가? 맥주를 사는 사람은 콜라도 같이 구매하는 경우가 많은가? | |
유형분석 | - 문서를 분류하거나 조직을 그룹으로 나눌 때, 또는 온라인 수강생들을 특성에 따라 분류할 때 사용 - 조직을 그룹으로 나눌 때 또는 온라인 수강생들을 특성에 따라 분류할 때 사용 |
예) 이 사용자는 어떤 특성을 가진 집단에 속하는가? | |
유전자 알고리즘 ★ | - 최적화가 필요한 문제의 해결책을 자연선택, 돌연변이 등과 같은 매커니즘을 통해 점진적으로 진화시켜 나가는 방법 (적자 생존) |
예) 최대의 시청률을 얻으려면 어떤 프로그램을 어떤 시간대에 방송해야 하는가? | |
기계학습 | - 훈련 데이터로 부터 학습한 알려진 특성을 활용해 예측하는 방법 |
예) 기존의 시청 기록을 바탕으로 시청자가 현재 보유한 영화 중에서 어떤 것을 가장 보고 싶어할까? | |
회귀분석 | - 독립변수를 조작함에 따라, 종속변수가 어떻게 변하는지를 보면서 두 변인의 관계를 파악할 때 사용 (인과관계) |
예) 구매자의 나이가 구매 차량의 타입에 어떤 영향을 미치는가? 고객 만족도가 충성도에 어떤 영향을 미치는가? | |
감정분석 (감성분석) ★ | - 특정 주제에 대해 말하거나 글을 쓴 사람의 감정을 분석 (트위터 형용사 분석) |
예) 새로운 환불 정책에 대한 고객의 평가는 어떤가? | |
소셜 네트워크 분석 (사회 관계망 분석) | - 특정인과 다른 사람이 몇 촌 정도의 관계인가를 파악할 때 사용하고, 영향력 있는 사람을 찾아낼 때 사용 (SNS 고객들 소셜 관계 파악) |
예) 고객들 간 관계망은 어떻게 구성되어 있나? |
#빅데이터 시대의 위기 요인★
| 내용 / 사례 | 해결책 |
사생활 침해 | - 개인정보가 포함된 데이터를 목적 외에 활용할 경우 사생활 침해를 넘어 사회, 경제적 위협으로 변형될 수 있다. | 동의에서 책임으로 빅데이터에 의한 사생활 침해 문제를 해결하기에는 부족한 측면이 많아 좀 더 포괄적인 해결책으로 동의제를 책임제로 바꾸는 방안을 제안한다. |
예) 여행 사실을 트윗한 사람의 집을 강도가 노리는 사례 발생 | ||
책임 원칙 훼손 | - 빅데이터 기본 분석과 예측 기술이 발전하면서 정확도가 증가한 만큼, 분석 대상이 되는 사람들은 예측 알고리즘의 희생양이 될 가능성도 올라간다. | 결과 기반 책임 원칙 고수 |
예) 범죄 예측 프로그램을 통해 범죄 전 체포 | ||
데이터 오용 | - 빅데이터는 일어난 일에 대한 데이터에 의존하기 때문에 이를 바탕으로 미래를 예측하는 것은 적지 않은 정확도를 가질 수 있지만 항상 맞을 수는 없다. 또한 잘못된 지표를 사용하는 것도 빅데이터의 폐해가 될 수 있다. | 알고리즘 접근 허용 알고리즘에 대한 접근권을 제공하여 알고리즘의 부당함을 반증할 수 있는 방법을 명시해 공개할 것을 주문한다. → 알고미즈미스트는 데이터오용의 피해를 막아주는 역할을 한다. |
#데이터 사이언스 ★
- 데이터로부터 의미있는 정보를 추출해내는 학문. ★
- 분석뿐 아니라 이를 효과적으로 구현하고 전달하는 과정까지를 포함한 포괄적 개념.
#데이터 사이언티스트의 요구역량
(1) 하드스킬(Hard Skill)
- 빅데이터에 대한 이론적 지식: 관련 기법에 대한 이해와 방법론 습득
- 분석 기술에 대한 숙련: 최적의 분석 설계 및 노하우 축적
(2) 소프트 스킬(Soft Skill)
- 통찰력 있는 분석: 창의적 사고, 호기심, 논리적 비판
- 설득력 있는 전달: 스토리텔링, 시각화
- 다분야간 협력: 커뮤니케이션
- 전략적 통찰을 주는 분석은 단순 통계나 데이터 처리와 관련된 지식 외에 인문학적 요소 (스토리텔링, 커뮤니케이션, 창의력, 열정, 직관력, 비판적 시각, 대화능력 등) 필요
- 가트너(Gartner)가 정의한 데이터 사이언티스트의 역량 ★
#전략적 통찰력과 인문학의 부활 ★
(1) 외부 환경적 측면에서 인문학 열풍의 이유
① 단순세계화 → 복잡 세계화
- 컨버전스(규모의 경제, 표준화) → 디버전스(복잡한 세계, 다양성)
② 상품 생산 → 서비스
- 고장나지 않은 상품 → 뛰어난 서비스
③ 생산 → 시장창조
- 공급자 중심 → 무형자산 경쟁(현지사회, 문화)
(2) 창의적 관점, 비즈니스 핵심가치 이해, 고객과 직원의 내면적 요구 이해하는 능력
#객체지향 DBMS ★
- 정보를 객체 형태로 표현하는 데이터베이스 모델
⇒ 복잡한 데이터 구조를 표현 및 관리
#개인정보 비식별화 기법 ★
- 데이터 마스킹 : 데이터를 익명으로 생성 (홍**, **대학)
- 가명처리 : 다른 값으로 대체 (홍국돈, 항곡대학)
- 총계처리 : 총합 값으로 대체 (키 합:750cm, 평균키:185cm)
- 데이터값 삭제 : 개인 식별에 중요한 값 삭제 (90년대 생, 남자)
- 데이터 범주화 : 범주의 값으로 변환 (홍씨, 30~40세)
단일식별 정보를 해당 그룹의 대표 값으로 변환
#블록체인 ☆
- 기존 금융회사의 중앙집중형 서버에 거래 기록을 보관하는 방식에서 거래에 참여하는 모든 사용자에게 거래 내역을 보내주며 거래 때마다 이를 대조하는 데이터 위조 방지 기술
- 네트워크에 참여하는 모든 사용자의 거래 내역 등의 데이터를 분석, 저장하는 기술을 지칭하는 용어. 공공거래장부, 분산거래장부로 불리기도 한다.
#맵리듀스 ☆
- 구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작하여 004년 발표한 소프트웨어 프레임 워크
2과목 - 데이터 분석 기획
#분석 주제 유형 ★
분석의 대상(What) → | Known | Un-Known |
Known | 최적화(Optimization) | 통찰(Insight) ★ |
Un-Known | 솔루션(Solution) ★ | 발견(Discovery) ★ |
#분석 기획 시 고려사항 ★
(1) 가용한 데이터
- 분석을 위한 데이터의 확보가 우선적이며, 데이터의 유형에 따라서 적용 가능한 솔루션 및 분석 방법이 다르기 때문에 데이터에 대한 분석이 선행적으로 이루어져야 한다.
예) 반정형 데이터: 센서 중심으로 스트리밍되는 머신 데이터
(2) 적절한 유스케이스
- 분석을 통해 가치가 창출될 수 있는 적절한 활용방안과 유스케이스의 탐색이 필요하다.
- 기존에 구현되어 활용되고 있는 유사 분석 시나리오/솔루션을 최대한 활용하는 것이 중요.
(3) 분석과제 수행을 위한 장애요소
- 분석을 수행함에 있어서 발생하는 장애요소들에 대한 사전 계획 수립이 필요
- 일회성 분석으로 그치지 않고 조직의 역량으로 내재화하기 위해서는 충분하고 계속적인 교육 및 활용방안 등의 변화 관리가 고려되어야 한다.
#빅데이터 기획 전문가 ★☆
- 회사 내 기능조직, 비즈니스 분석 또는 BI조직에 소속되어 있으면서 빅데이터 분석 전문 조직과 협력을 통하여 업무에 필요한 분석 모델이나 예측 모델을 Self Service Analytics 도구를 활용하여 구현하는 전문가
#분석방법론의 구성요소 ★
- 절차, 방법, 도구와 기법, 템플릿과 산출물
#방법론의 적용 업무의 특성에 따른 모델
(1) 폭포수 모델(Waterfall model)
- 단계를 순차적으로 진행하는 방법으로, 이전 단계가 완료되어야 다음 단계로 진행될 수 있으며 문제가 발견되면 피드백 과정이 수행
(2) 나선형 모델(Spiral model) ★
- 대규모 시스템 소프트웨어 개발에 적합 여러 변의 개발 과정을 거쳐 점진적으로 프로젝트를 완성시켜가는 모델
- 반복을 통해 점증적으로 개발하는 방법으로 처음 시도하는 프로젝트에 적용이 용이하지만 관리 체계를 효과적으로 갖추지 못한 경우 복잡도가 상승하여 프로젝트 진행이 어렵다
(3) 프로토타입 모델(Waterfall model)
- 폭포수 모델의 단점을 보완하기 위해 점진적으로 시스템을 개발해 나가는 접근 방법
- 고객의 요구를 완전하게 이해하고 있지 못하거나 완벽한 요구 분석의 어려움을 해결하기 위하여 개발의 일부분만을 우선 개발한다.
- 사용자는 시험 사용을 하게 되고 이를 통해서 요구를 분석하거나 요구 정당성을 점검, 성능을 평가하여 그 결과를 개선 작업에 반영
#ISP(Information Strategy Planning) ★☆
- 기업 및 공공기관에서 시스템의 중장기 로드맵을 정의하기 위해 수행한다. 정보기술 또는 정보시스템을 전략적으로 활용하기 위하여 조직 내/외부 환경을 분석하여 기회나 문제점을 도출하고 사용자의 요구사항을 분석하여 시스템 구축 우선순위를 결정하는 등 중장기 마스터 플랜을 수립하는 절차이다.
#데이터 분석을 위한 조직 구조 ★
집중 구조 ★ | - 전사 분석업무를 별도의 분석전담조직이 담당 |
기능 구조 | - 일반적인 분석 수행 구조 |
분산 구조 ★ | - 분석조직 인력들을 현업업무로 직접 배치하여 분석업무 수행 |
#플랫폼 ★☆
- 단순한 분석 응용프로그램 뿐만 아니라 분석 서비스를 위한 응용 프로그램이 실행될 수 있는 기초를 이루는 컴퓨터 시스템을 의미한다.
- 분석 플랫폼이 구성되어 있는 경우, 새로운 데이터 분석 니즈가 존재할 때 개별적인 분석 시스템을 추가하는 방식이 아닌 서비스를 추가로 제공하는 방식으로 확장성을 높일 수 있다.
예) 페이스북은 SNS 서비스로 시작했지만, 2006년 F8 행사를 기점으로 자신들의 소셜그래프 자산을 외부 개발자들에게 공개하고 서드파티 개발자들이 페이스북 위에서 작동하는 앱을 만들기 시작했다. 각종 사용자 데이터나 M2M 센서 등에서 수집된 데이터를 가공, 처리, 저장해 두고, 이 데이터에 접근할 수 있도록 API를 공개하였다.
#KDD 분석 절차
(1) 데이터셋 선택
- 데이터셋 선택에 앞서 분석 대상 비즈니스 도메인의 대한 이해와 프로젝트 목표 설정
- 데이터베이스 또는 원시 데이터에서 분석에 필요한 데이터 선택
- 데이터마이닝에 필요한 목표 데이터 구성
(2) 데이터 전처리 ★
- 추출된 분석 대상용 데이터셋에 포함되어 있는 잡음과 이상치, 결측치를 식별하고 필요시 제거하거나 의미있는 데이터로 재처리하여 데이터셋을 정제
- 데이터 전처리 단계에서 추가로 요구되는 데이터 셋이 있을 경우 데이터셋 선택 프로세스 재실행
(3) 데이터 변환
- 데이터 전처리 과정을 통해 정제된 데이터에 분석 목적에 맞는 변수를 생성, 선택하고 데이터의 차원을 축소하여 효율적으로 데이터마이닝을 할 수 있도록 변경
- 학습용 데이터와 시험용 데이터로 분리
(4) 데이터마이닝
⓵ 목적 설정 ⓶ 데이터 준비 ⓷ 가공 ⓸ 기법 적용 ⓹ 검증 ★
- 학습용 데이터를 이용해서 분석 목적에 맞는 데이터마이닝 기법을 선택하고 적절한 알고리즘을 적용하여 데이터마이닝 작업 실행
- 필요에 따라 데이터 전처리와 데이터 변환 프로세스를 추가로 실행하여 최적 결과 산출
(5) 결과 평가
- 데이터마이닝 결과에 대한 해석과 평가 그리고 분석 목적과의 일치성을 확인
- 활용 방안 마련 및 필요에 따라 이전 프로세스를 반복 수행
#CRISP-DM 프로세스
6단계로 구성되어 있으며, 각 단계는 한 방향으로 구성되어 있지 않고 단계 간 피드백을 통해 단계별 완성도를 높이게 되어 있다.
(1) 업무이해
- 비즈니스 관점에서 프로젝트의 목적과 요구사항을 이해하기 위한 단계로써 도메인 지식을 데이터 분석을 위한 문제정의로 변경하고 초기 프로젝트 계획을 수립하는 단계
- 분석 절차 실패 발생 단계 ★
⇒ 업무 목적 파악, 상황 파악, 데이터 마이닝 목표 설정, 프로젝트 계획 수립
(2) 데이터 이해
- 분석을 위한 데이터를 수집하고 데이터 속성을 이해하기 위한 과정으로 데이터 품질에 대한 문제점을 식별하고 숨겨져 있는 인사이트를 발견하는 단계이다.
⇒ 초기 데이터 수집, 데이터 기술 분석, 데이터 탐색, 데이터 품질 확인
(3) 데이터 준비 ★
- 분석을 위해 수집된 데이터에서 분석 기법에 적합한 데이터로 편성하는 단계로써 많은 시간이 소요될 수 있다.
KDD의 데이터 전처리와 같은 단계
⇒ 데이터셋 선택, 데이터 정제, 데이터셋 편성, 데이터 통합
(4) 모델링
- 다양한 모델링 기법과 알고리즘을 선택하고 모델링 과정에서 사용되는 파라미터를 최적화해 나가는 단계이다. 데이터셋이 추가로 필요한 경우 데이터 준비 단계를 반복 수행할 수 있으며, 모델링 결과를 테스트용 데이터셋으로 평가하여 모델 과적합 문제를 확인한다.
⇒ 모델링 기법 선택, 모델 테스트 계획 설계, 모델 작성, 모델 평가 ★
(5) 평가
- 모델링 결과가 프로젝트 목적에 부합하는지 평가하는 단계로 데이터마이닝 결과를 최종적으로 수용할 것인지 판단한다.
⇒ 분석결과 평가, 모델링 과정 평가, 모델 적용성 평가 ★
(6) 전개
- 모델링과 평가 단계를 통해 완성된 모델을 실제 업무에 적용하기 위한 계획을 수립하고 모니터링과 모델의 유지보수 계획을 마련한다. 모델은 적용되는 비즈니스 도메인의 특성, 입력되는 데이터 품질 편차, 운영모델의 평가 기준에 따라 생명주기가 다양하므로 상세한 전개 계획이 필요하다.
- 프로젝트 종료 관련 프로세스를 수행하여 프로젝트를 마무리한다.
⇒ 전개계획 수립, 모니터링과 유지보수 계획 수립, 프로젝트 종료보고서 작성, 프로젝트 리뷰
#비지도 학습과 지도 학습 ☆
구분 | 비지도학습 | 지도학습 |
기법 | 장바구니 분석 | 의사결정나무 ★ |
예시 | 고객의 과거 거래 구매 패턴을 분석했다. | 대출 가능한 고객을 분류했다. |
(1) 비지도학습
- 일반적으로 상향식 접근방식의 데이터 분석 비지도 학습 방법에 의해 수행된다.
- 비지도학습은 데이터분석의 목적이 명확히 정의된 형태의 특정 필드의 값을 구하는 것이 아니라 데이터 자체의 결합, 연관성, 유사성 등을 중심으로 데이터의 상태를 표현하는 것이다.
예) 장바구니 분석, 군집 분석, 연관분석, OLAP, SOM, 기술 통계 및 프로파일링 등
(2) 지도학습
- 명확한 목적 하에 데이터를 분석하는 것으로 분류, 추측, 예측, 최적화를 통해 분석을 실시하고 지식을 도출한다.
예) 의사결정나무, 인공신경망, 회귀분석, K-NN 등 사례기반 추론
#빅데이터 분석 방법론 ★
(1) 분석 기획 | ① 비즈니스 이해 및 범위 설정 ② 프로젝트 정의 및 계획 수립 ③ 프로젝트 위험계획 수립 |
(2) 데이터 준비 | ① 필요 데이터 정의 ② 데이터 스토어 설계 ③ 데이터 수집 및 정합성 점검 |
(3) 데이터 분석 | ① 분석용 데이터 준비 ② 텍스트 분석 ③ 탐색적 분석 ④ 모델링 ⑤ 모델 평가 및 검증 |
(4) 시스템 구현 | ① 설계 및 구현 ② 시스템 테스트 및 운영 |
(5) 평가 및 전개 | ① 모델 발전 계획 수립 ② 프로젝트 평가 및 보고 |
(1) 분석 기획
② 프로젝트 정의 및 계획 수립
- SOW(Statement Of Work) 작성 ★
- 입력자료 : 중장기계획서, 빅데이터분석 프로젝트 지시서, 비즈니스 이해 및 도메인 문제점
- 프로세스 및 도구 : 자료 수집, 비즈니스 이해, 프로젝트 범위 정의서 작성 절차
- 출력자료 : 프로젝트 범위 정의서 SOW
③ 프로젝트 위험계획 수립
- 위험관리: 회피, 전이, 완화, 수용 ★
(2) 데이터 준비
① 필요 데이터 정의
- 데이터 정의서를 이용하여 구체적인 데이터 획득 방안을 상세하게 수립함으로써 데이터 획득 과정에서 발생하는 프로젝트 지연을 방지한다.
- ERD: 운영중인 데이터베이스와 일치하기 위해 철저한 변경관리가 필요하다. ★
② 데이터 스토어 설계
- 데이터 스토어는 정형·비정형·반정형 데이터를 모두 저장할 수 있도록 설계한다.
| 정형 데이터 스토어 설계 | 비정형 데이터 스토어 설계 |
입력자료 | 데이터 정의서, 데이터 획득 계획서 | 데이터 정의서, 데이터 획득 계획서 |
프로세스 및 도구 | 데이터베이스 논리설계, 데이터베이스 물리설계, *데이터 매핑 | 비정형, 반정형 데이터 논리설계, 비정형, 반정형 데이터 물리설계 |
출력자료 | 정형 데이터 스토어 설계서, 데이터 매핑 정의서 | 비정형 데이터 스토어 설계서, 데이터 매핑 정의서 |
*데이터 매핑: 두 개의 서로 다른 데이터 모델이 만들어지고 이러한 모델 간의 연결이 정의되는 프로세스
(3) 데이터 분석
데이터 분석 단계를 수행하는 과정에서 추가적인 데이터 확보가 필요한 경우 데이터 준비 단계로 피드백하여 두 단계를 반복 진행한다. ★
④ 모델링 ★
- 분석용 데이터를 이용한 가설 설정을 통해 통계 모델을 만들거나 기계학습을 이용한 데이터의 분류, 예측, 군집 등의 기능을 수행하는 모델을 만드는 과정
- 기계학습은 지도학습과 비지도학습 등으로 나뉘어 다양한 알고리즘을 적용할 수 있다. 모델링을 효과적으로 진행하기 위해서는 모델링 전에 데이터셋을 훈련용과 시험용으로 분할함으로써 모델의 과적합을 방지하거나 모델의 일반화에 이용된다.
#하향식(Top-down) 접근 방식 ★
- 하향식 접근방식은 문제가 정형화되어 있고 문제해결을 위한 데이터가 완벽하게 조직에 존재할 경우에 효과적이다.
(1) 문제 탐색 (Problem discovery) | · 비즈니스 모델 기반 문제 탐색 · 외부 참조 모델 기반 문제 탐색 · 분석 유스 케이스 정의 |
(2) 문제 정의 (Problem definition) | |
(3) 해결방안 탐색 (Solution search) | |
(4) 타당성 검토 (Feasibility study) ★ | |
(1) 문제 탐색 (Problem discovery)
· 비즈니스 모델 기반 문제 탐색 ★
- 거시적 관점(STEEP)에서 비즈니스 분석하는 5가지 영역, 경쟁자 확대 관점에서 분석 기회 발굴 3가지 영역, 시장의 니즈 탐색 관점에서 분석 기회 발굴 3가지 영역, 역량의 재해석 관점에서 분석 기회 발굴 2가지 영역
· 외부 참조 모델 기반 문제 탐색
· 분석 유즈 케이스 정의
- 현재의 비즈니스 모델 및 유사/동종 사례탐색을 통해서 빠짐없이 도출한 분석 기회들을 구체적인 과제로 만들기 전에 분석 유스 케이스로 표기하는 것이 필요하다.
(2) 문제 정의 (Problem definition)
- 분석을 수행하는 당사자뿐만 아니라 최종 사용자 관점에서 이루어져야 한다.
(3) 해결방안 탐색(Solution search)
- 분석 역량을 가지고 있는지 여부를 파악하여 과제를 해결하는 방안에 대해 사전 검토 수행
(4) 타당성 검토(Feasibility study) ★
- 도출된 분석 문제나 가설에 대한 대안을 과제화하기 위해서는 다각적(경제적, 기술적 및 데이터) 타당성 분석이 수행되어야 한다. ★
- 기술적 타당성 분석 시 적용 가능한 요소기술 확보 방안에 대한 사전 고려가 필요하다. ★
#상향식(Bottom-up) 접근 방식
(1) 기존 하향식 접근법의 한계를 극복하기 위한 분석 방법론
- 하향식 접근 방식은 새로운 문제의 탐색에는 한계가 있다. 따라서 최근 복잡하고 다양한 환경에서 발생하는 문제에는 적합하지 않을 수 있다.
- "Why"가 아니라 "What" 관점에서 보아야 한다.
- 답을 미리 내는 것이 아니라 사물을 있는 그대로 인식하는 "What" 관점에서 보아야 한다.
- 객관적으로 존재하는 데이터 그 자체를 관찰하고 실제적으로 행동에 옮김으로써 대상을 좀 더 잘 이해하는 방식으로의 접근을 수행하는 것이다.
(2) 시행착오를 통한 문제 해결
- 프로토타이핑 접근법은 사용자의 요구사항이나 데이터를 정확히 규정하기 어렵고 데이터 소스도 명확히 파악하기 어려운 상황에서 일단 분석을 시도해보고 그 결과를 확인해가면서 반복적으로 개선해 나가는 방법.
- 비록 완전하지는 못하다 해도 신속하게 해결책이나 모형을 제시함으로써 문제를 좀 더 명확하게 인식하고 필요한 데이터를 식별하여 구체화할 수 있게 하는 유용한 접근 방식.
#프로토타이핑의 필요성
- 문제에 대한 인식 수준
- 필요 데이터 존재 여부의 불확실성
- 데이터 사용 목적의 가변성
#디자인 사고(Design thinking) ★
- 새로운 상품을 개발하거나 전략수립 등 중요한 의사결정을 할 때 가능한 옵션을 도출하는 상향식 접근 방식의 발산(Diverge) 단계와 도출된 옵션을 분석하고 검증하는 하향식 접근 방식의 수렴(Converge) 단계를 반복적으로 수행하며 상호 보완한다.
- 동적인 환경에서 분석의 가치를 높일 수 있는 최적의 의사결정 방식
#분석 프로젝트 관리방안 ★
- KSA ISO 21500의 프로젝트 관리 주제 그룹: 통합, 이해관계자, 범위, 자원, 시간, 원가, 리스크, 품질, 조달, 의사소통
- 분석 프로젝트의 최종 산출물이 보고서/시스템인지에 따라 프로젝트 관리에 차이가 있다.★
범위 (Scope) | 분석 프로젝트의 최종 산출물이 보고서 또는 시스템인지에 따라 프로젝트 관리에 차이가 있다. ★ |
시간 (Time) | 데이터 분석 프로젝트는 초기에 의도했던 모델이 쉽게 나오지 않기 때문에 지속적으로 반복되어 많은 시간이 소요될 수 있다. 분석프로젝트의 일정 계획 수립 시 데이터 수집에 대한 철저한 통제, 관리할 필요가 없다. ★ 분석 결과에 대한 품질이 보장된다는 전제로 Time Boxing 기법으로 일정관리를 진행하는 것이 필요하다. |
품질 (Quality) | 분석 프로젝트를 수행한 결과에 대한 품질목표를 사전에 수립하여 확정해야 한다. 품질을 평가하기 위해서 SPICE를 활용할 수 있다. ★ |
#ROI 관점에서 빅데이터의 핵심 특징
(1) 투자비용 요소 ⇒ Investment
- Volume, Variety, Velocity
(2) 비즈니스 효과 요소 ⇒ Return ★
가치(Value) : 분석 결과를 활용하거나 실질적인 실행을 통해 얻게 되는 비즈니스 효과 측면의 요소로서, 기업의 데이터 분석을 통해 추구하거나 달성하고자 하는 목표 가치.
#데이터 분석 과제를 추진할 때 고려해야 하는 우선순위 평가 기준 ★
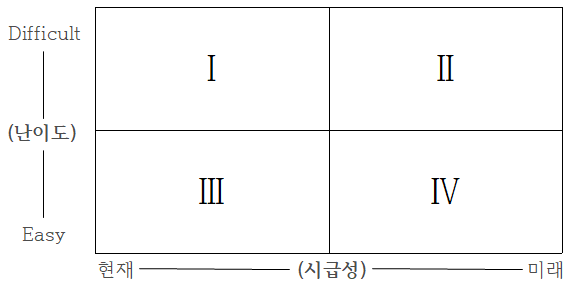
- 분석과제의 적용 우선순위 기준을 "시급성"에 둔다면 3→4→2 영역 순이며,
- 우선순위 기준을 "난이도"에 둔다면 3→1→2 영역 순으로 의사결정을 할 수 있다. ★
#데이터 분석 수준진단 프레임워크
(1) 분석 준비도
- 기업의 데이터 분석 도입의 수준을 파악하기 위한 진단방법
- 분석 업무 파악, 인력 및 조직, 분석 기법, 분석 데이터, 분석 문화, IT 인프라
- 일정 수준 이상 충족하면 분석 업무 도입, 충족하지 못할 시 분석 환경 조성
분석 업무 파악 | 인력 및 조직 | 분석기법 |
· 발생한 사실 분석 업무 | · 분석전문가 직무 존재 | · 업무별 적합한 분석기법 |
분석 데이터 | 분석 문화 | IT 인프라 |
· 분석업무를 위한 데이터 | · 사실에 근거한 의사결정 | · 운영시스템 데이터 통합 |
(2) 분석 성숙도 모델
- 조직 성숙도 평가 도구 : CMMI(Capability Maturity Model Integration) 모델 ★☆
- 분석 성숙도 진단 분류: 비즈니스 부문, 조직·역량 부문, IT 부문
- 성숙도 수준 분류 (도입 → 활용 → 확산 → 최적화)
(1) 도입 (도입형) | · 분석 시작 환경과 시스템 구축 |
(2) 활용 (준비형) ☆ | · 분석 결과를 실제 업무에 적용 |
(3) 확산 (확산형) | · 전사 차원에서 분석을 관리하고 공유 |
(4) 최적화 (정착형) | · 분석을 진화시켜서 혁신 및 성과 향상에 기여 |
#분석 과제 관리를 위한 5가지 주요 영역 ★
(1) 데이터 크기 (Data size)
- 분석하고자 하는 데이터의 양을 고려한 관리 방안 수립이 필요하다.
(2) 데이터 복잡성 (Data complexity)
- 비정형 데이터 및 다양한 시스템에 산재되어 있는 원천 데이터들을 통합해서 분석 프로젝트를 진행할 때는, 초기 데이터의 확보와 통합 뿐 아니라 해당 데이터에 잘 적용될 수 있는 분석 모델의 선정 등에 대한 사전 고려가 필요하다.
(3) 속도 (Speed)
- 분석결과가 도출되었을 때 이를 활용하는 시나리오 측면에서의 속도를 고려해야함
(4) 분석 복잡성 (Analytic complexity)
- 분석 모델의 정확도와 복잡도는 Trade-off 관계가 존재하므로 이에 대한 기준점을 사전에 정의해 두어야 한다.
- 분석 모델이 복잡할수록 정확도는 올라가지만 해석이 어려워진다.
- 해석이 가능하면서도 정확도를 올릴 수 있는 최적 모델을 찾는 방안을 사전 모색
(5) 정확도와 정밀성 (Accuracy & Precision) ★
- Accuracy와 Precision은 Trade-off 되는 경우가 많으므로 사전에 고려하여야 한다.
- Accuracy (활용성) : 모델과 실제 값 사이의 차이가 적다는 정확도
- Precision (안정성) : 모델을 지속적으로 반복했을 때의 편차의 수준, 일관적으로 동일한 결과를 제시한다는 것을 의미
#분석 거버넌스 체계 ★
(1) 분석 기획 및 관리를 수행하는 조직 (Organization) ★
(2) 과제 기획 및 운영 프로세스 (Process) ★
(3) 분석 관련 시스템 (System)
(4) 데이터 (Data)
(5) 분석 관련 교육 및 마인드 육성 체계 (HR) ★
#분석마스터플랜 고려 요소 ★
(1) 업무 내재화 적용 수준
(2) 기술 적용 수준
(3) 분석 데이터 적용 수준
#데이터 거버넌스 ★☆
- 전사 차원의 모든 데이터에 대하여 정책 및 지침, 표준화, 운영조직 및 책임 등의 표준화된 관리 체계를 수립하고 운영을 위한 프레임워크 및 저장소를 구축하는 것
- 빅데이터 거버넌스를 산업분야별, 데이터 유형별, 정보 거버넌스 요소 별로 구분하여 작성한다. ★
#데이터 거버넌스 관리 대상 ★☆
(1) 마스터 데이터(Master Data),
(2) 메타 데이터(Meta Data)
(3) 데이터 사전(Data Dictionay)
#데이터 거버넌스 구성 요소 ★
(1) 원칙(Principle)
(2) 조직(Organization)
(3) 프로세스(Process)
#데이터 거버넌스 체계 ★
(1) 데이터 표준화 ★
- 데이터 표준 용어 설정, 명명 규칙(Name rule) 수립, 메타 데이터 구축, 데이터 사전 구축
(2) 데이터 관리 체계 ★
- 표준 데이터를 포함한 메타 데이터와 데이터 사전의 관리 원칙을 수립
(3) 데이터 저장소 관리 Repository
- 메타데이터 및 표준 데이터를 관리하기 위한 전사 차원의 저장소를 구성
(4) 표준화 활동
- 데이터 거버넌스 체계를 구축한 후 표준 준수 여부를 주기적으로 점검, 모니터링 실시
#데이터저장소 ★☆
- 데이터 거버넌스 체계에서 데이터 저장소(Repository) 관리란 메타 데이터 및 표준 데이터를 관리하기 위한 전사 차원의 저장소로 구성된다. 저장소는 데이터 관리 체계 지원을 위한 워크플로우 및 관리용 응용소프트웨어를 지원하고 관리 대상 시스템과의 인터페이스를 통한 통제가 이뤄져야 한다. 또한 데이터 구조 변경에 따른 사전영향평가도 수행되어야 효율적인 활용이 가능하다.
3과목 - 데이터 분석
#데이터마이닝 ★
- 대표적인 고급 분석으로 데이터에 있는 패턴을 파악해 예측하는 분석으로, 데이터가 크고 정보가 다양할수록 활용하기 유리한 분석
#데이터마이닝의 평가 기준 ★
(1) 정확도
(2) 정밀도
(3) 리프트
(4) 디텍트 레이트
#R
- R은 오픈소스 프로그램으로 통계, 데이터마이닝을 위한 언어이다.
- 윈도우, 맥, 리눅스 OS에서 사용 가능하다.
- 객체 지향 언어이며 함수형 언어로서 자동화가 가능하다. ★
- 벡터의 원소 중 하나라도 문자가 있으면 모든 원소의 자료형은 문자 형태로 변환 ★
#패키지 자동설치
install.packages(“패키지”) ★
#데이터 변경 및 요약
(1) plyr을 이용한 데이터 분석 ★
- plyr는 multi-core를 사용하여 반복문을 사용하지 않고도 매우 간단하고 빠르게 처리할 수 있는 데이터 처리 함수를 포함하고 있는 패키지다. ★
- apply 함수에 기반해 데이터와 출력변수를 동시에 배열로 치환하여 처리하는 패키지
#summary() ★
- 연속형 변수의 경우 4분위수, 최소값, 최대값, 중앙값, 평균 등을 출력하고 범주형 변수의 경우 각 범주에 대한 빈도수를 출력하여 데이터의 분포를 파악할 수 있게 하는 함수
#데이터 프레임과 데이터 구조 ★
(1) 벡터(Vector)
- 하나의 스칼라 값 혹은 하나 이사의 스칼라 원소들을 가진다. ★
- 벡터들은 동질적이다: 한 벡터의 원소는 모두 같은 자료형을 가진다.
- 벡터는 인덱스를 통해 여러 개의 원소로 구성된 하위 벡터를 반환할 수 있다.
- 벡터 원소들은 이름을 가질 수 있다.
(2) 데이터프레임(Data frame) ★
- 표 형태의 구조이며, 각 열은 서로 다른 데이터 형식을 가질 수 있다. ★
- 데이터프레임 리스트의 원소는 벡터 또는 요인이다. (벡터와 요인 = 데이터 프레임의 열)
- 벡터와 요인들은 동일한 길이이다.
- 메모리상에서 구동된다.
- 열에는 이름이 있어야하며, 각각의 열에 대해 문자형인지 수치형인지 자동적으로 구분된다.
기능 | R 코드 |
행결합 | rbind(dfrm1, dfrm2) newdata ← rbind(data, row) ★ |
열결합 | cbind(dfrm1, dfrm2) newdata ← cbind(data, col) ★ |
(3) 데이터 구조 및 자료형 변환
기능 | R 코드 |
자료형 변환 | as.integer() ★ 예) as.interger(3, 14)의 값은 3이다.
as.numeric() ★
as.logical() ★ 예) as.logical(0, 45)의 값은 TRUE이다. |
(4) 데이터 구조 변경
기능 | R 코드 |
벡터 → 리스트 | as.list(vector) |
벡터 → 행렬 | 1열짜리 행렬: cbind(vector) 또는 as.matrix(vector) 1행짜리 행렬: rbind(vector) ★ n * m 행렬: matrix(vector, n, m) |
행렬 → 벡터 | as.vector(matrix) |
(5) 문자열, 날짜 다루기
기능 | R 코드 |
문자열 길이 | nchar("단어") ★ |
날짜 객체로 변환 | as.Date( ) format(Sys.Date(), format=%m%d%y)
*문자열을 Date 객체로 변환하려면 as.Date(string, format=) 명령을 사용한다. ★ |
#기초 분석 및 데이터 관리
(1) EDA(Exploratory Data Analysis, 탐색적 자료 분석) ★
- 데이터가 가지고 있는 특성을 파악하기 위해 변수의 분포 등을 시각화하여 분석하는 방식
- 데이터 분석에 앞서 전체적으로 데이터의 특징을 파악하고 데이터를 다양한 각도로 접근
- EDA의 4가지 주제: 저항성의 강조, 잔차 계산, 자료변수의 재표현, 그래프를 통한 현시성
(2) 결측값(Missing value)
- 결측값 자체가 의미 있는 경우도 있다.
- 결측값이나 이상값을 꼭 제거해야 하는 것은 아니기 때문에 분석의 목적이나 종류에 따라 적절한 판단이 필요하다.
- R에서는 결측값을 NA로 표기한다. ★
(3) 결측값 처리 방법(Imputation)
단순 대치법 (Single Inputation) | completes analysis : 결측값이 존재하는 레코드를 삭제 | |
평균대치법 (mean imputation) ★ : 자료의 평균값으로 결측값을 대치하여 불완전한 자료를 완전한 자료로 만들어 분석한다. | 비조건부 평균 대치법 : 관측 데이터의 평균 | |
조건부 평균 대치법 : 회귀분석을 활용 | ||
단순 확률 대치법 (Single Stochastic Imputation) ★ : 평균대치법에서 추정량 표준 오차의 과소 추정문제를 보완하고자 고안된 방법이다. 예) Hot-deck 방법, nearest neighbor 방법 등 | ||
다중 대치법 (Multiple Imputation) | 단순 대치법을 한 번 적용하지 않고 m번의 대치를 통해 m개의 가상적 완전 자료를 생성 | |
(4) 이상값 탐지(detection)
① ESD(Extreme Studentized Deviation) ★☆
- 평균으로부터 K*표준편차만큼 떨어져 있는 값들을 이상값으로 판단하는 방법
② (-1.5 * IQR(Q3-Q1) < data < 1.5 * IQR)의 범위를 벗어나는 값
#이상치 ★
- 설명변수의 관측치에 비해 종속 변수의 값이 상이한 값
#통계분석
- 통계분석 방법을 이용해 의사결정하는 과정
- 기술통계 : 여러 특성을 수향화하는 통계 분석 방법론 (평균, 표준편차, 그래프)
- 통계적 추론 (추측통계) : 모집단으로부터 추출된 표본의 표본통계량으로부터 모집단의 특성인 모수에 관해 통계적으로 추론하는 통계 (모수추정, 가설점정, 예측) ★☆
#표본조사 ★
(1) 표본 오차(sampling error)
- 모집단을 대표하는 표본 단위들이 조사 대상으로 추출되지 못함으로써 발생하는 오차
(2) 비표본 오차(non-sampling error)
표본오차를 제외한 모든 오차로서 조사과정에서 발생하는 모든 부주의나 실수, 알 수 없는 원인 등 모든 오차
- 조사대상이 증가하면 오차가 커진다.
- 표본 값으로 모집단의 모수를 추정할 때 표본오차의 비표본오차가 발생할 수 있다.
(3) 표본 편의(sampling bias)
- 모수를 작게 또는 크게 할 때 추정하는 것과 같이 표본추출방법에서 기인하는 오차
- 표본 편의는 확률화(randomization)에 의해 최소화하거나 없앨 수 있다. ★
- 확률화(randomization): 모집단으로부터 편의되지 않은 표본을 추출하는 절차
- 확률 표본(random sample): 확률화 절차에 의해 추출된 표본
(4) 표본조사에서 유의해야할 점 ★
- 응답오차, 유도질문 등
#표본추출의 방법 ★☆
(1) 단순 랜덤 추출법
- 각 원소에 임의 번호 부여 후 n개의 번호를 임의 선택 ★
(2) 계통 추출법 ★
번호를 부여한 샘플을 나열하여 k개씩 n개의 구간을 나누고 첫 구간에서 하나를 임의로 선택한 후에 k개씩 띄어서 표본을 선택하고 매번 k번째 항목을 추출하는 방법 ★☆
① 모집단의 모든 원소에 일련번호 부여, 순서대로 나열
② k개 씩 n개의 구간으로 나눈다
③ 각 구간에서 하나를 임의로 선택 ★
(3) 집락 추출법
- 일부 집락을 랜덤으로 선택 후 각 집락에서 표본을 임의 선택 ★
(4) 층화 추출법 ★
- 모집단을 성격에 따라 몇 개의 집단 또는 층으로 나누고, 각 집단 내에서 원하는 크기의 표본을 무작위로 추출하는 확률적 표본 추출 방법
① 서로 유사한 것끼리 몇 개의 층으로 나눈다.
② 표본을 랜덤하게 추출
#자료의 종류
척도 | 순서 | 균등한 간격 | 절대적 존재 |
명목척도 | x | x | x |
서열척도 | o | x | x |
구간척도 | o | o | x |
비율척도* | o | o | o |
*비율척도는 사칙연산이 가능하다.
질적 자료 (qualitative data)
(1) 명목척도
- 어느 집단에 속할지(Yes/No)
예) 성별, 출생지 등
(2) 서열척도(순서척도)
- 서열관계, 선택사항이 일정한 순서로 되어 있음
예) 선호도(Good/Medium/Bad) 등
양적 자료(quantitative data)
(3) 구간척도(등간척도)
- 속성의 양을 측정, 비율은 별 의미 없음
- 절대적인 원점 존재하지 않음
예) 온도, 지수 등
(4) 비율척도
- 절대적 기준인 0값 존재, 사칙연산 가능
- 숫자로 관측되는 일반적인 자료의 특성
예) 무게, 나이, 연간소득, 제품 가격 등
#교차 분석 (Crosstabs Analysis) ★☆
- 범수의 관찰도수에 비교될 수 있는 기대도수를 계산한다.
- 두 문항 모두 범주형 변수일 때 사용하며, 두 변수 간 관계를 보기 위해 실시한다.
- 교차 표를 작성하여 교차빈도를 집계할 뿐 아니라 두 변수 간의 독립성 검정을 할 수 있다.
- 기대빈도가 5 미만인 셀의 비율이 20%를 넘으면 카이제곱분포에 근사하지 않으며 이런 경우 표본의 크기를 늘리거나 변수의 수준을 합쳐 셀의 수를 줄이는 방법 등을 사용한다.
#조건부 확률과 독립사건
- 조건부 확률 P(B|A) = P(A n B) / P(A) - P(A)>0 일 때만 정의된다.
- P(A n B)=P(A)P(B)이면, 두 사건이 독립이라는 의미.
- P(B|A)=P(B)일 경우, 사건 B의 확률은 사건 A가 일어났는지 여부와 무관하다.
#이산형 확률 변수 ★
- 사건의 확률이 "점", 확률이 0보다 큰 값을 갖는 점들로 표현 가능
- 각 이산점에 있어서 확률의 크기를 표현하는 함수 → 확률 질량 함수 ★
(1) 베르누이 확률분포 ★
- 결과가 2개만 나오는 경우 (ex. 동전 던지기, 합격/불합격)
- 각 사건이 성공할 확률이 일정하고 전/후 사건에 독립적인 특수한 상황의 확률 분포
(2) 포아송분포 ★☆
- 주어진 시간, 공간 내에서 발생하는 사건 횟수에 대한 확률 분포
#연속형 확률 변수
- 어떤 0보다 큰 값을 갖는 함수의 면적으로 표현
- 한 점에서의 확률은 0, 구간에서의 확률 값 → 확률밀도함수 ★
(1) 균일분포(일양분포)
(2) 정규분포
(3) 지수분포
(4) t-분포: 두 집단의 평균이 동일한 지 확인하기 위해 검정통계량으로 활용
(5) 카이제곱분포: 모평균, 모분산이 알려지지 않은 모집단의 모분산 가설 검정과 동질성 검정
(6) F-분포: 두 집단 간 분산의 동일성 검정에 사용
이산형 확률 분포 | 연속형 확률 분포 |
베르누이 확률분포 포아송분포 ☆ 다항분포 초기하분포 | 균일분포 |
#목표변수가 연속형인 경우 회기나무의 경우 사용하는 분류기준 ★
- 분산감소량, F통계량의 p값 등
#모분산의 추론 ★
- 표본의 분산은 카이제곱 분포를 따른다.
- 모집단의 변동성 또는 퍼짐의 정도에 관심이 있는 경우 모분산이 추론의 대상이 된다.
- 모집단이 정규 분포를 따르지 않더라도 중심극한정리를 통해 정규모집단으로부터 모분산에 대한 검정을 유사하게 시행할 수 있다.
#추정과 가설검정 ★
통계적 추론 | |||
(1) 추정 | (2) 가설검정 | ||
점추정 | 구간추정 | ||
#통계적 추론
- 모집단에서 추출된 표본을 기반으로 모수들에 대한 통계적 추론을 한다.
→ 추정과 가설검정으로 나뉨.
- 모집단의 평균(모평균)을 추정하기 위한 추정량 = 표본평균 (확률표본의 평균값)
- 모집단의 분산(모분산)을 추정하기 위한 추정량 = 표본분산
#점 추정 ★
- 가장 참값이라고 여겨지는 하나의 모수의 값을 택하는 것.
- 모수가 특정한 값일 것 이라고 추정하는 것.
#구간추정
- 모수가 특정한 구간에 있을 것이라는 개념으로 신뢰구간을 추정하는 방법
- 모수의 참값이 포함되어 있다고 추정되는 구간을 결정하는 것이지만, 실제 모집단의 모수가 신뢰구간에 꼭 포함되어 있는 것은 아니다. ★
- 신뢰수준: 90%, 95%, 99%의 확률을 이용하는 경우가 많다.
- 신뢰수준 95%: '주어진 한 개의 신뢰구간에 미지의 모수가 포함될 확률 95%;라는 의미 ★
- 신뢰구간: 일정한 크기의 신뢰 수준으로 모수가 특정 구간에 있을 것이라 선언하는 것 ★
- 신뢰수준이 높아지면 신뢰수준의 길이는 길어진다. ★
- 표본의 수가 많아지면 신뢰구간의 길이는 짧아진다. ★
- 모집단의 확률분포를 정규분포라 가정할 때, 95% 신뢰수준 하에서 모평균 μ 의 신뢰구간
#자유도(degree of freedom) ★
- 통계적 추정을 할 때 표본자료 중 모집단에 대한 정보를 주는 독립적인 자료 수
- 크기가 n인 표본의 관측값의 자유도(df)는 n-1이다 ★
#p-value ★
- 옳다는 가정 하에 얻은 통계량이 귀무가설을 얼마나 지지하는지 나타낸 확률 ★
- 귀무가설이 사실인데도 불구하고 사실이 아니라고 판정할 때 실제 확률 ★
- 미리 정해놓은 유의수준 값보다 작을 경우 귀무가설은 기각, 대립가설은 채택 ★
- 0~1 사이의 값을 가지며, 전체 표본에서 하나의 표본이 나올 수 있는 확률 ★
- p-value가 작을수록 귀무가설을 기각할 가능성이 높아진다.
#가설검정 ★
- 모집단에 대한 귀무가설(H0)과 대립가설(H1)을 설정한 뒤, 표본관찰 또는 실험을 통해 하나를 선택하는 과정
- 귀무가설이 옳다는 전제하에서 관측된 검정통계량의 값보다 더 대립가설을 지지하는 값이 나타날 확률을 구하여 가설의 채택여부 결정한다.
- 독립변수의 기울기(회귀계수)가 0이라는 가정을 귀무가설, 기울기가 0이 아니라는 가정을 대립가설로 놓는다. ★★
- 즉 유의수준을 평가하여 귀무가설을 채택할지 거부할지를 판단한다.★
- 귀무가설(H0) : 대립가설과 반대의 증거를 찾기 위해 정한 가설 (관습적/보수적인 주장)
- 대립가설(H1) : 증명하고 싶은 가설 (적극적으로 우리가 입증하려는 주장) ★
- 유의수준(알파a): 오류를 허용할 범위
- 유의확률(p-value): 대립가설이 틀릴 확률 ★
#가설검정의 오류 ★
- 1종 오류 : 귀무가설이 사실인데도 사실이 아니라고 판정 ★
- 2종 오류 : 귀무가설이 사실이 아님에도 사실이라고 판정
- 제1종 오류와 제2종 오류는 상충관계가 있음
- 기각역 : 귀무가설을 기각하는 통계량의 영역(대립가설이 맞을 때 그것을 받아들이는 확률)
정확한 사실/가설검정 결과 | 귀무가설(H0)이 사실이라고 판정 | 귀무가설(H0)이 사실이 아니라고 판정 |
귀무가설(H0)이 사실임 | 옳은 결정 | 제 1종 오류(α) ★ |
귀무가설(H0)이 사실이 아님 | 제2종 오류(β) | 옳은 결정 |
#분포의 형태에 관한 측도
(1) 왜도
- 분포의 비대칭 정도를 나타내는 측도
- Right-skewed, Positive-skewed distribution (오른쪽으로 긴 꼬리를 갖는 분포 ) ★
: Mode < Median < Mean
- Symmetrical distribution
: Mode = Median = Mean
- Left-skewed, Negative-skewed distribution (왼쪽으로 긴 꼬리를 갖는 분포 )
: Mean < Median < Mode
(2) 첨도
- 분포의 중심에서 뾰족한 정도를 나타내는 측도
#검정 통계량
- 검정 통계량은 모수를 추정하고자 하는 것
- 귀무가설을 기각을 할지 말지는 모수로부터 검정 통계량이 얼마나 떨어져 있는데 따라서 판단한다.
#t 검정(t-test)
- 모집단의 분산이나 표준편차를 알지 못할 때 모집단을 대표하는 표본으로부터 추정된 분산이나 표준편차를 가지고 검정하는 방법
- “두 모집단의 평균 간의 차이는 없다”라는 귀무가설과 “두 모집단의 평균 간에 차이가 있다”라는 대립가설 중에 하나를 선택할 수 있도록 하는 통계적 검정방법
모수적 검정 | - 가설의 설정 : 가정된 분포의 모수(모평균, 모분산 등)에 대한 가설 설정 - 검정 실시 : 관측된 자료를 이용해 표본평균, 표본분산 등을 구하여 이용 |
비모수적 검정 | - 가설의 설정 : 가정된 분포가 없으므로, 단지 '분포의 형태' 동일 여부에 대해 가설 설정 - 모집단의 분포에 아무 제약을 가하지 않고 검정을 실시하는 검정 방법★ - 모집단에 대한 아무런 정보가 없을 때 사용하는 방법★ - 관측 자료가 특정분포를 따른다고 가정할 수 없는 경우에 이용 ★ - 평균과 분산이 없으므로 평균 값의 차이, 신뢰구간을 구할 수 없다. ★ - 절대적인 크기에 의존하지 않는 관측 값의 순위나 부호 등을 이용★ - 모집단의 특성을 몇 개의 모수로 결정하기 어려우며 수많은 모수가 필요할 수 있다.★ 예) 부호검정, 순위합검정, 부호순위합검정, U검정, 런검정, 순위상관계수, 크루스칼-왈리스 검정, 맨-휘트니 검정 등 |
#부호 검정(Sign test) ★
- 비모수 검정 방법 ★
- 표본들이 서로 관련되어 있는 경우 짝지어진 두 개의 관찰치들의 크고 작음을 표시하여 그 개수를 가지고 두 분포의 차이가 있는지에 대한 가설을 검증하는 방법
- 이 표본에 의한 분산비 검정은 두 표본의 분산이 동일한지를 비교하는 검정으로 검정통계량은 F분포를 따른다.
#표본을 도표화함으로써 모집단 분포의 개형을 파악하는 방법
(1) 히스토그램 ★
- 도수분포표를 이용하여 표본자료의 분포를 나타낸 연속형 그래프
- 수평축 위에 계급구간을 표시, 각 계급의 상대도수에 비례하는 넓이의 직사각형을 그린 것
(2) 줄기-잎 그림 ★
- 각 데이터의 점들을 구간단위로 요약하는 방법으로 계산량이 많지 않음
(3) 산점도 ★
- 두 특성의 값이 연속적인 수인 경우, 표본자료를 그래프로 나타내는 방법
- 각 이차원 자료에 대해 좌표가 (특성 1의 값, 특성 2의 값)인 점을 좌표평면 위에 찍은 것
(4) 파레토그림 ★
- 명목형 자료에서 ‘중요한 소수’를 찾는데 유용한 방법
#회귀분석의 정의와 변수의 종류
- 회귀분석이란 하나나 그 이상의 변수들이 또 다른 변수에 미치는 영향에 대해 추론할 수 있는 통계기법이다.
- 반응변수(종속변수) : 영향을 받는 변수, 보통 y로 표기
- 설명변수(독립변수) : 영향을 주는 변수, 보통 x, x1, x2 등으로 표기
- 회귀계수 추정 : 최소제곱법, 최소자승법 ★
#회귀모형에 대한 가정 ★☆
- 선형성 : 독립변수의 변화에 따라 종속변수도 변화하는 선형인 모형 ★
- 독립성 : 잔차와 독립변수의 값이 관련되어 있지 않음 ★
- 등분산성 : 오차항들의 분포는 동일한 분산을 가짐
- 비상관성 : 잔차들끼리 상관이 없어야 함
- 정상성(정규성) : 잔차항이 정규분포를 이뤄야 함 ★☆
#정규성 검정 ★
(1) Q-Q plot ★
(2) Shapiro-Wilk test (샤피로 – 윌크 검정) ★
(3) Kolmogorov-Smirnov test(콜모고로프-스미노프 검정)
(4) 히스토그램
#최소제곱 ★☆
주어진 자료를 가장 잘 설명하는 회귀계수의 추정치는 보통 제곱오차를 최소로 하는 값을 구하며, 이 회귀계수 추정량을 최소제곱이라고 한다.
#회귀분석 모형에서 확인할 사항
(1) 모형이 통계적으로 유의미한가?
⇒ F 분포 값과 유의확률 (p-value)를 확인
(2) 회귀계수들이 유의미한가?
⇒ 회귀계수의 T 값과 유의확률 (p-value)를 확인
(3) 모형이 얼마나 설명력을 갖는가?
⇒ R^2(결정계수)를 확인, 0~1값
(4) 모형이 데이터를 잘 적합하고 있는가?
⇒ 잔차통계량을 확인하고 회귀진단
#다중선형회귀분석 결과 해석
- 모형의 통계적 유의성은 F-통계량으로 확인
유의수준 5% 하에서 F-통계량의 p-value 값이 0.05보다 작으면 추정된 회귀식은 통계적으로 유의하다고 볼 수 있음
- F-통계량이 크면 p-value가 0.05보다 작아지고 귀무가설을 기각. 모형이 유의하다고 결론
#다중공선성 (Multicolinearity)
- 모형의 일부 예측변수가 다른 예측변수와 상관되어 있을 때 발생하는 조건
- 중대한 다중공선성은 회귀계수의 분산을 증가시켜 불안정하고 해석하기 어렵게 만들기 때문에 문제가 된다.
- R에서는 VIF 함수를 이용해 VIF값을 구할 수 있으며, 보통 VIF값이 4가 넘으면 다중공선성이 존재한다고 본다.
- 해결방안 : 높은 상관 관계가 있는 예측변수를 모형에서 제거한다.
#인과관계와 공분산의 이해
- 종속변수(반응변수): 다른 변수의 영향을 받는 변수
- 독립변수(설명변수): 영향을 주는 변수
- 산점도: 두 변수 사이의 선형, 함수 관계 파악, 이상값, 집단 구분 확인 가능
- 공분산: 두 변수의 방향성 확인, 독립이면 Cov(X,Y) = 0 ★
#최적 회귀방정식의 선택 ★☆
(1) 모든 가능한 조합의 회귀분석
- 모든 가능한 독립변수들의 조합에 대한 회귀모형을 고려해 가장 적합한 회귀모형을 선택
- AIC나 BIC의 값이 가장 작은 모형을 선택하는 방법으로 모든 가능한 조합의 회귀분석을 실시한다. ★
(2) 전진선택법 (Forward Selection)
- 상수모형으로부터 시작해 중요하다고 생각되는 설명변수부터 차례로 모형에 추가
- 후보가 되는 설명변수 중 가장 설명을 잘하는 변수가 유의하지 않을 때의 모형을 선택
- 설명변수를 추가했을 때 제곱합의 기준으로 가장 설명을 잘하는 변수를 고려하여 그 변수가 유의하면 추가한다. ★☆
(3) 후진제거법 (Backward Elimination) ★☆
- 독립변수 후보 모두를 포함한 모형에서 출발해 가장 적은 영향을 주는 변수부터 제거
- 더 이상 유의하지 않은 변수가 없을 때의 모형을 선택
(4) 단계별방법 (Stepwise Selection)
- 기존의 모형에서 예측 변수를 추가, 제거를 반복하여 최적의 모형을 찾는 방법 ★☆
- 더 이상 추가 또는 제거되는 변수가 없을 때의 모형을 선택
(5) 적은 수의 설명변수
- 가능한 범위 내 적은 수의 설명변수를 포함시킨다. ★☆
#경사하강법(Gradient descent)★
- 손실을 줄이는 알고리즘으로 미분값(기울기)이 최소가 되는 점을 찾아 가중치를 찾는 방법
#세 가지 정규화 방법의 비교
구분 | 릿지(Ridge) | 라쏘(Lasso) ★ | 엘라스틱넷(Elastic Net) |
제약식 | L2norm | L1norm ★ | L1 + L2norm |
변수선택 | 불가능 | 가능 | 가능 |
장점 | 변수 간 상관관계가 높아도 좋은 성능 | 변수 간 상관관계가 높으면 성능이 떨어짐 | 변수 간 상관관계를 반영한 정규화 |
#Lasso 회귀분석 ★
- 회귀분석에서 사용하는 최소제곱법에 제약조건을 부여하는 방법이다.
- 회귀계수의 절대값이 클수록 패널티를 부여한다. ★
- 자동적으로 변수선택을 하는 효과가 있다. ★
- lambda값으로 penalty의 정도를 조정한다. ★
- MSE(평균제곱오차, mean squared error)와 Penalty항의 합이 최소가 되게 하는 파라메터를 찾는 것이 목적이다.
#상관분석 ★
- 데이터 안의 두 변수 간의 관련성을 파악하는 방법이다.
- 상관계수는 두 변수 간 관련성의 정도를 의미하며, 유의성은 판단할 수 없다. ★
- 두 변수간 선형 관계의 크기를 측정하는 공분산의 크기가 단위에 따라 영향을 받지 않도록 한 피어슨 상관계수에서 두 변수의 상관관계가 존재하지 않을 경우 도출되는 값은 0이다.★
#상관분석 유형 ★
(1) 피어슨의 상관계수
- 두 변수 간의 선형관계의 크기를 측정하는 값으로 비선형적인 관계는 나타내지 못한다.★
- 연속형 변수만 가능, 정규성을 가정
- 대상이 되는 자료의 종류 : 등간척도, 비율척도 ★★
- ‘-1’과 ‘1’ 사이의 값을 가진다.★
예) 국어 점수와 영어점수의 상관계수
(2) 스피어만 상관계수 ★★
- 두 변수 간의 비선형적인 관계도 나타낼 수 있음 ★★
- 연속형 외에 이산형 순서형도 가능 ★
- 관계가 랜덤이거나 존재하지 않을 경우 상관 계수 모두 0에 가깝다. ★
- 원시 데이터가 아니라 각 변수에 대해 순위를 매긴 값(서열)을 기반으로 한다. ★
- 비모수적이다.
- 대상이 되는 자료의 종류 : 순서척도, 서열척도 ★★
- ‘-1’과 ‘1’ 사이의 값을 가진다.
- 0은 상관 관계가 없음을 의미한다.
예) 국어성적 석차와 영어성적 석차의 상관계수
#상관계수와 상관관계 ★
- 상관계수 r의 범위는 -1 ≤ r ≤ 1
- 상관계수가 0에 가까울수록 상관이 낮다고 한다
- ‘r=0’은 두 변수 간 직선적 관계가 없다는 의미
#결정계수★
- 결정계수는 총 변동 중 회귀모형에 의하여 설명되는 변동이 차지하는 비율이다. ★
- 결정계수가 커질수록 회귀방정식의 설명력이 높아진다.
- 수정된 결정계수는 유의하지 않은 독립변수들이 회귀식에 포함되었을 때 값이 감소한다. ★
- 다중회귀분석에서는 최적 모형의 선정기준으로 결정계수 값보다 수정된 결정계수 값을 사용하는 것이 적절하다. ★☆
- 회귀모형에서 입력변수가 증가하면 결정 계수도 증가한다.
- 결정계수는 0~1 사이의 범위를 갖는다.
- 회귀계수의 유의성 검증은 t값과 p값을 통해 확인하다.
(1) 총 제곱합(총 변동, SST) = 회귀제곱합(설명된 변동, SSR) + 오차제곱합(그 외 변동, SSE)
(2) R^2(결정계수) = 회귀제곱합(SSR) / 총 제곱합(SST) ★
→ 결정계수가 클 수록 회귀방정식과 상관계수의 설명력이 높아진다.★
#주성분분석(PCA, Principal Component Analysis)
- p개의 변수들을 중요한 m(p)개의 주성분으로 표현하여 전체 변동을 설명하는 방법 ★
- 데이터에 많은 변수가 있을 때 변수의 수를 줄이는 차원 감소 기법
- 상관관계가 있는 변수들을 선형 결합하여 변수를 축약
#주성분분석 개수(m)를 선택하는 방법★☆
- 전체 변이 공헌도(percentage of total variance) 방법은 전체 변이의 70~90% 전도가 되도록 주성분의 수를 결정한다.
- 평균 고유값 방법: 교유값들의 평균을 구한 후 고유값이 평균값 이상이 되는 주성분을 설정하는 것 (삭제하는 것이 아님)
- Scree graph를 이용하는 방법은 고유값의 크기순으로 산점도를 그린 그래프에서 감소하는 추세가 원만해지는 지점에서 1을 뺀 개수를 주성분의 개수로 선택한다.
- 주성분은 주성분을 구성하는 변수들의 계수 구조를 파악하여 적절하게 해석되어야 하며, 명확하게 정의된 해석 방법이 있는 것은 아니다.
#주성분분석 vs 요인분석
- 자료의 축소라는 차원에서 같은 의미로 해석하기 쉬우나 다른 개념
- 주성분분석 : 많은 데이터에 포함된 정보의 손실을 최소화해서 데이터를 단순 축소하는 법
- 공통요인분석 : 자료의 축소라는 의미도 포함해 데이터에 내재적 속성까지 찾아내는 법
#시계열 자료
- 시간의 흐름에 따라 관찰된 값들을 시계열 자료라 한다.
- 시계열 데이터 분석을 통해 미래를 예측하고 경향, 주기, 계절성 등을 파악하여 활용한다.
- 시계열 데이터의 구성요소: 추세, 순환, 계절변동, 불규칙 변동 등 ★
#시계열 데이터의 분석 절차 ★
(1) 시간 그래프 그리기
(2) 추세와 계절성을 제거
(3) 잔차를 예측
(4) 잔차에 대한 모델 적합하기
(5) 예측된 잔차에 추세와 계절성을 더해 미래 예측
#시계열 구성 요소 ★☆
(1) 추세 요인
- 장기적으로 변해가는 큰 흐름 → 상승, 하락, 이차식, 지수식 형태
(2) 계절 요인 ☆
- 요일, 월, 분기 등 고정된 주기에 따른 변화
(3) 순환 요인
- 명백한 이유없이 알려지지 않은 주기를 가지고 변화
(4) 불규칙 요인
- 불규칙하게 변동하여 급격한 환경변화, 천재지변 같은 것으로 발생하는 변동
- 위 세 가지 요인으로 설명할 수 없는 회귀분석의 오차에 해당하는 요인
#정상성
- 시간의 흐름에 따라 관측된 시계열 자료를 분석하기 위해서는 정상성을 만족해야 함
- 정상성이란, 시점에 관계없이 시계열의 특성이 일정함을 의미
- 확률과정의 평균과 분산이 일정한 것을 안정적이라고 함
#정상성의 조건 ★
(1) 평균이 일정
(2) 분산이 시점에 의존하지 않음
(3) 공분산은 시차에만 의존하고, 시점 자체에는 의존하지 않음 ★
- 위 3가지 조건을 만족하지 못하는 경우 비정상시계열이며, 대부분의 자료가 비정상 시계열
- 시계열 자료의 분석을 위해서는 이를 판단하고, 분석 가능한 형태로 바꾸는 작업이 필요함
#차분 ★☆
- 비정상 시계열이 정상성을 만족하도록 수정하는 방법
- 현 시점의 자료 값에서 전 시점의 자료 값을 빼는 것
#분해 시계열 ★☆
- 상시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법
- 시계열에 영향을 주는 일반적인 요인을 분리해 분석 하는 방법
#지수평활법(Exponential Smoothing)
(1) 지수평활법의 개념
- 일정 기간의 평균을 이용하는 이동평균법과 달리 모든 시계열 자료를 사용하여 평균을 구하며, 시간의 흐름에 따라 최근 시계열에 더 많은 가중치를 부여하여 미래를 예측하는 방법
*평활법이란 변화가 심한 시계열 데이터를 평탄하고 변화가 완만하게 값을 변환시키는 것 ★
#자기회귀모형 (AR 모형) ☆
- 시계열 모델 중 자신의 과거 값을 사용하여 설명하는 모형 ☆
- 백색 잡음의 현재값과 자기 자신의 과거값의 선형 가중합으로 이루어진 정상 확률 모형 ☆
- 모형에 사용하는 시계열 자료의 시점에 따라 1차, 2차, …, p차 등을 사용하나 정상시계열 모형에서는 주로 1,2차를 사용함. ☆
- 과거 시점의 관측 자료의 선형 결합으로 표현하는 것
#이동평균모형 (MA 모형) ★
- 현 시점의 자료를 p 시점 전까지 유한 개의 백색잡음들의 선형결합으로 표현
- 항상 정상성을 만족하는 모형으로, 정상성 가정이 필요없다..
- 백색 잡음의 현재 값과 자기 자신의 과거값의 선형 가중합으로 이루어진 정상 확률 모형
- 과거 시점의 백색잡음의 선형결합으로 표현하는 것
#자기회귀 누적이동평균모형 (ARIMA 모형) ★
- ARIMA는 AR모형과 MA모형을 합친 모형이다. AR(p) + MA(q)
- 자동회귀이동평균(ARMA : Autoregressive moving average) 모델의 일반화
- 기본적으로 비정상 시계열 모형
- 차분, 변환을 통해 AR모형이나 MA모형, ARMA 모형으로 정상화
- ARIMA(p,d,q), p:AR모형, d:차분 횟수, q:MA모형 차수 ★
#다차원척도법 ★☆
- 객체 간 근접성을 시각화하는 통계기법
- 군집분석과 같이 개체들을 대상으로 변수들을 측정한 후에 개체들 사이의 유사성/비유사성을 측정하여 개체들을 2차원 또는 3차원 공간상에 점으로 표현하여 개체들 사이의 집단화를 시각적으로 나타내는 분석방법 ★
- 개체들 사이의 유사성/ 비유사성을 측정하여 2차원 또는 3차원 공간상에 표현하는 방법
- 개체간의 근접성을 시각화하여 데이터 속에 잠재한 패턴이나 구조를 찾아내는 통계기법
- 차원의 수가 많을수록 추정의 적합도가 높아지지만 해석이 어려워진다.
- 유사성의 계산은 Euclidean 거리를 활용한다.
- 여러 대상 간의 거리가 주어져 있을 때, 대상들을 동일한 상대적 거리를 가진 실수 공간의 점들로 배치시키는 방법
#다차원척도법 목적
- 데이터 속에 잠재해 있는 패턴과 구조를 찾아낸다. ★
- 그 구조를 소수 차원의 공간에 기하학적으로 표현한다. ★
- 데티어 축소의 목적으로 다차원척도법을 이용한다.
- 즉, 데이터에 포함되는 정보를 끄집어내기 위해서 다차원척도법을 탐색수단으로써 사용한다.
- 다차원척도법에 의해 얻은 결과를, 데이터가 만들어진 현상이나 과정에 고유의 구조로서 의미를 부여한다.
#다차원척도법 종류
(1) 계량적 MDS (Metric MDS)
- 데이터가 구간척도나 비율척도인 경우 활용한다. ★
(2) 비계량적 MDS (Monmetric MDS)
- 데이터가 순서척도인 경우 활용한다. 개체들간의 거리가 순서로 주어진 경우에는 순서척도를 거리의 속성과 같도록 변환하여 거리를 생성한 후 적용한다. ★
#오즈비 (Odds ratio), 승산비 ☆
- 한 집단이 다른 집단에 비해 성공할 승산 비에 대한 측정량
- 클래스 0에 속할 확률 (1-p)이 클래스 1에 속할 확률 p의 비
- 오즈비 = 성공률/실패율 = Pi/(1–Pi) (단, Pi는 성공률) ★
- exp(beta)의 의미는 나머지 변수가 주어질 때,  이 한 단위 증가할 때마다 성공(Y=1)의
이 한 단위 증가할 때마다 성공(Y=1)의
- 오즈(odds)가 몇 배 증가하는지 나타내는 값 ★
- 성공 가능성이 높은 경우는 1보다 크고, 실패 가능성이 높은 경우는 1보다 작다
#데이터 마이닝의 정의 ★
- 대용량 데이터 속에서 숨겨진 지식 또는 새로운 규칙을 추출해 내는 과정 ★
- 기업이 보유한 고객, 거래, 상품데이터 등과 이외의 기타 외부 데이터를 기반으로 감춰진
- 지식, 새로운 규칙 등을 발견하고 이를 비즈니스 의사결정 등에 활용하는 일련의 작업
#데이터 마이닝 ★☆
1) 분류(Classification) ★☆
- 새롭게 나타난 현상을 검토하여 기존의 분류, 정의된 집합에 배정 하는 것
- 반응변수가 범주형인 경우 예측모형의 주목적
2) 추정(Estimation)
3) 예측(Prediction)
4) 연관 분석(Association Analysis)
5) 군집(Clustering) ★☆
- 이질적인 모집단을 세분화하는 기능
6) 기술(Description) ★
- 데이터가 가지고 있는 의미를 단순하게 기술하여, 의미를 파악할 수 있도록 함 ★
#데이터 마이닝 5단계 ★
1) 목적 정의
2) 데이터 준비 (수집개념)
- 데이터 마이닝 수행에 필요한 데이터 수집
3) 데이터 가공 ★ (가공개념)
- 모델링 목적에 따라 변수를 정의하고, 소프트웨어 적용에 적합하도록 데이터를 가공한다.
4) 데이터 마이닝 기법의 적용
5) 검증
#데이터 사이언스 ☆
- 데이터로부터 의미있는 정보를 추출해내는 학문
- 분석에 초점을 두는 데이터마이닝과 달리, 효과적으로 구현/전달하는 포괄적 개념
#로지스틱 회귀모형 정의
- 독립변수(x)와 종속변수 (y) 사이의 관계를 설명하는 모형으로 종속변수가 범주형 (y=0 또는 y=1)값을 갖는 경우에 사용하는 방법
#로지스틱 회귀모형 특징
- 반응변수가 범주형인 경우 적용한다.
- 일반화선형모형의 특별한 경우로 로짓(logit) 모형으로도 불린다. ★
- 오즈(odds)의 관점에서 해석될 수 있다는 장점을 가진다.
- 새로운 설명변수가 주어질 때, 반응변수의 각 범주에 속할 확률이 얼마인지 추정한다.
- 클래스가 알려진 데이터에서 설명변수들의 관점에서 각 클래스내의 관측치에 대한 유사성을 찾는데 사용할 수 있다. ★
- 설명변수가 한 개일 때 회귀계수(β)의 부호에 따라 S자(β>0) 또는 역S자(β<0) 모양을 가짐
(설명변수가 한 개, 해당 회귀계수의 부호가 0보다 작은 경우 표현되는 그래프 : 역S자 ★)
#선형회귀분석 vs 로지스틱 회귀분석
1) 최소자승법(최소제곱법) ★☆
- 데이터와 추정된 함수가 얼마나 잘 맞는지는 잔차들을 제곱(square)해서 구한다. 이를 잔차제곱합(RSS or SSE)이라고 한다.
- 최소제곱법은 해당 식이 제곱형태이니 미분해서 0이 되는 지점을 찾기 위해 잔차제곱합을 최소화하는 계수를 구하는 방법이다.
구분 | 일반선형 회귀분석 | 로지스틱 회귀분석 |
종속변수 | 연속형 변수 | 이산형 변수 |
모형 탐색 방법 | 1) 최소자승법 ★ | 2) 최대우도법, 가중최소자승법 |
모형 검정 | F 검정, t 검정 | 3) 카이제곱 검정 ★ |
2) 최대우도법
- 관측 값이 가정된 모집단에서 하나의 표본으로 추출된 가능성이 가장 크게 되도록 하는 회귀계수 추정방법
- 표본의 수가 클 경우에 최대우도법은 안정적이다.
3) 카이제곱 검정 ★
- 분류 조합에 따라 특정 값에 유효한 차이가 발생하는 지를 검정하는 것으로 명목 척도로
- 측정된 두 속성이 서로 관련되어 있는지 분석하고 싶을 때 사용하는 통계분석법
- 독립변수와 종속변수가 모두 명목척도일 경우 적합한 통계 기법
#신경망 모형의 정의 및 특징
장점 | 단점 |
- 변수의 수가 많거나, 입ㆍ출력 변수 간에 복잡한 비선형 관계가 존재할 때 유용 | - 결과에 대한 해석이 쉽지 않음 |
#인공신경망 모형 ☆
- 인간 뇌를 기반으로 한 추론 모델 ★
- 뉴런은 가중치가 있는 링크들로 연결
- 뉴런은 여러 입력 신호를 받지만 출력 신호는 오직 하나만 생성
- 변수의 수가 많거나 입출력 변수 간 복잡한 비선형관계가 존재할 때 유용 ★
- 잡음에 대해서도 민감하게 반응하지 않는다. ★
#뉴런
- 입력링크에서 여러 신호를 받아 새로운 활성화 수준을 계산, 출력링크로 출력 신호를 보냄.
- 입력 신호는 미가공 데이터 또는 다른 뉴런의 출력이 될 수 있다.
- 출력 신호는 문제의 최종적인 해(solution)가 되거나 다른 뉴런에 입력될 수 있다.
- 뉴런은 활성화 함수를 사용한다.
- 뉴런은 입력 신호의 가중 합을 계산하여 임계값과 비교한다.
- 가중치 합이 임계값보다 작으면 뉴런의 출력은 –1, 같거나 크면 +1을 출력한다.
#포화문제 ★
- 역전파를 진행함에 따라 각 노드를 연결하는 가중치의 절대값이 커져 조정이 더 이상 이루어지지 않아 과소 적합이 발생하는 문제
#기울기 소실 문제(Gradient Vanishing) ★☆
- 다층 신경망모형에서 은닉층의 개수를 너무 많이 설정하게 되면 역전파 과정에서 앞쪽 은닉층의 가중치 조정이 이뤄지지 않아 신경망의 학습이 제대로 이뤄지지 않는 현상
#역전파 알고리즘
- 신경망 모형의 목적함 수를 최적화하기 위해 사용된다. ★
- 연결강도를 갱신하기 위해 예측된 결과와 실제 값의 차이(에러)를 통해 가중치를 조정하는 방법 ★
#과대적합(Overfitting) ★☆
- 학습 데이터는 실제 데이터의 일부분이므로 너무 과하게 학습하게 되면 학습데이터는 정확하게 맞지만 실제 데이터에 대해서 오차가 증가하는 문제 ★
- 생성된 모델이 훈련 데이터에 너무 최적화되어 학습하여 테스트데이터의 작은 변화에 민감하게 반응한다.
- 학습 데이터가 모집단의 특성을 충분히 설명하지 못할 때 자주 발생한다.
- 과대적합이 발생할 것으로 예상되면 학습을 종료하고 업데이트를 반복하여 방지할 수 있다.
- 조기 종료 : 검증 오차가 증가하기 시작하면 반복 중지
- 가중치 감소 : 벌점화 기법 활용
#신경망 모형 구축 시 고려사항
1) 입력 변수
- 복잡성에 의하여 입력 자료 선택에 민감
- 범주형 변수: 모든 범주에서 일정 빈도 이상, 빈도 일정
- 범주형 변수의 경우, 모든 범주형 변수가 같은 범위를 갖도록 가변수화 해야 함.
- 연속형 변수: 입력 변수들의 범위가 변수 간 큰 차이가 없을 때
- 연속형 변수의 경우, 분포가 평균 중심으로 대칭이야 함
2) 가중치의 초기 값과 다중 최소값 문제
- 초기 값은 0근처로 랜덤하게 선택, 가중치가 증가할수록 비선형
- 가중치가 0이면, 신경망 모형은 근사적 선형 모형
3) 학습모드
- 온라인 학습모드: 관측 값을 순차적으로 투입하여 가중치 추정 값이 매번 바뀜
(속도 빠름, 훈련 자료가 비정상성일 때 좋음, 국소 최소값에 벗어나기 쉬움)
- 확률적 학습모드: 관측 값을 랜덤하게 투입하여 가중치 추정 값이 매번 바뀜
- 배치 학습모드: 전체 훈련자료를 동시에 투임
4) 은닉층과 은닉 노드의 수 ★
- 신경망 적용 시 제일 중요한 부분: 모형 선택 (은닉층, 은닉노드의 수 결정)
- 은닉층의 뉴런 수를 정하는 것은 신경망을 설계하는 사람의 직관과 경험에 의존 ★
- 많으면 가중치가 많아져 과대 적합 문제 발생
- 은닉층 수 결정 : 하나로 선정
- 은닉노드 수 결정 : 적절히 큰 값을 놓고 가중치 감소시키면서 적용하는 것이 좋음
- 은닉층/노드가 많으면 가중치가 많아져 과적합 문제 발생 ★
- 은닉층/노드가 적으면 복잡한 의사결정 경계를 만들 수 없음
(입력 데이터를 충분히 표현하지 못하는 경우 발생 ★)
#뉴런의 활성화 함수
Soft Function | Sigmoid Function |
logistic regression에서 multi-classification 문제에서 사용 | logistic regression에서 binary-classification 문제 에서 사용 |
확률의 총 합 = 1 | 확률의 총 합은 1이 아님 |
출력 층에서 사용됨 (확률 표현) | Activation 함수로 사용될 수 있음 (실제 사용하지 않음) |
큰 출력 값은 그 class에 해당할 가능성이 높다는 것을 뜻하며 실제 확률을 나타냄 | 큰 출력 값은 그 class에 해당할 가능성이 높지만 실제 확률 값을 나타내는 것은 아님 |
(1) 소프트맥스(Softmax) 함수 ★☆
- 함수 결과 값(확률값) : 0 ≤ y ≤ 1, 모든 확률의 합은 1과 같다. ★
- 표준화지수 함수, 출력 값이 여러 개 주어지고 목표치가 다범주인 경우 각 범주에 속할 사후확률을 제공
(2) 시그모이드(Sigmoid) 함수
- 함수 결과 값(확률값) : 0 ≤ y ≤ 1 ★
- 로지스틱 회귀분석과 유사하다.
- 입력층이 직접 출력층에 연결되는 단층신경망에서 활성함수를 시그모이드로 사용하면 로지스틱 회귀 모형과 작동 원리가 유사해진다.
#neuralnet 함수의 일반화 가중치(generalized weight)
- 일반화 가중치(generalized weight)는 각 공변량의 영향을 표현하기 때문에 회귀모델에서 1번째 회귀 변수의 유사한 해석을 가진다.
- 로지스틱 회귀 모형에서의 회귀 계수와 유사하게 해석된다. ★☆
#FP-Growth ★
- Apriori 알고리즘의 약점을 보완하기 위한 방법
- 트리와 노드링크라는 특별한 자료 구조를 사용하는 알고리즘
#기계학습 ☆
- 훈련 데이터로부터 학습하여 알려진 특성을 활용해 예측
- 기존 시청기록을 바탕으로 영화 추천
#의사결정나무 정의와 특징
- 분류함수를 의사결정 규칙으로 이뤄진 나무 모양으로 그리는 방법
- 의사결정나무는 분류(classification)와 회귀(regression) 모두 가능하다.
- 복잡하지 않고 빠르게 만들 수 있다.
- 분류 정확도가 좋은 편이다.
- 다중공선성 영향을 안 받는다.
- 대표적 적용 사례: 대출신용평가, 환자 증상 유추, 채무 불이행 가능성 예측 ★
- 과적합의 문제를 해결하기 위해 정지규칙과 가지치기 방법을 이용하여 트리를 조정한다. ★
- 불순도 측도인 엔트로피 개념은 정보이론의 개념을 기반으로 하여, 임의의 사건이 모여있는 집합의 순수성(purity) 또는 단일성(homogeneity) 관점의 특성을 정량화해서 표현한 것 ★
장점 | 단점 |
구조가 단순하여 해석이 용이하다. | 분류 기준값의 경계선 부근의 자료값에 대해서는 오차가 크다. |
선형성, 정규성, 등분산성 등의 수학적 가정이 불필요한 *비모수적 모형 | 로지스틱회귀와 같이 각 예측변수의 효과를 파악하기 어렵다. |
수치형/범주형 변수를 모두 사용할 수 있다. | 새로운 자료에 대한 예측이 불안정할 수 있다. |
*비모수적 : 모수에 대한 가정을 전제로 하지 않고 모집단의 형태에 관계없이 주어진 데이터에서 직접 확률을 계산
#가지치기(Pruning) ★
- 의사결정나무 모형에서 과대적합되어 현실 문제에 적응할 수 있는 적절한 규칙이 나오지 않는 현상을 방지하기 위해 사용되는 방법
- 분류 오류를 크게 할 위험이 높으나 부적절한 규칙을 가지고 있는 가지를 제거하는 작업
#정지규칙 ★
- 의사결정나무에서 더 이상 분기가 되지 않고 현재의 마디가 끝마디가 되도록 하는 규칙
#이산형 목표변수와 연속형 목표변수 ★
- 목표변수가 범주형인 경우 분류나무, 수치형인 경우 회귀나무를 사용한다.★
- 목표변수가 이산형인 경우 분류나무, 연속형인 경우 회귀나무로 구분된다.
- 이산형 목표변수 : p 값은 작을수록, 지니지수와 엔트로피 지수는 클수록 노드 내의 이질성이 크고 순수도가 낮다고 할 수 있다.
- 연속형 목표변수 : p값은 작아지고 분산의 감소량은 커질 수록 이질성이 높다.
#의사결정나무 알고리즘 분류 및 기준변수의 선택법 ★
| (1) 이산형 목표변수 (분류나무) | (2) 연속형 목표변수 (회귀나무) |
(3) CHAID ★ | 카이제곱 통계량 | ANOVA F 통계량 |
(4) CART ★ | 지니계수 | 분산 감소량 |
(5) C5.0 | 엔트로피지수 |
|
(1) 목표변수가 이산형 목표변수인 경우 분류 기준
- 각 범주에 속하는 빈도에 기초하여 분리
- 오차율 분할 (잘못 분류된 관찰값의 수 / 전체 관찰값의 수)
- 카이제곱 통계량: 각 셀에 대한 (기대도수-실제도수)^2/기대도수 의 합
- 지니계수: 불평등 지수를 나타낼 때 사용하는 계수로 0이 가장 평등, 1로 갈수록 불평등
엔트로피지수: 엔트로피 지수가 가장 작은 예측 변수와 이때의 최적분리에 의해 자식마디를 형성함
(2) 목표변수가 연속형 목표변수인 경우 분류 기준 ★
- 평균과 표준편차에 기초하여 분리
- 잔차제곱합(SSR) 개선되는 방향으로 분할 (불필요한 지도학습 / 분산은 높고 편향은 낮다.)
- F통계량 : 모델 또는 모델 성분의 유의성을 검정하는
- 분산분석(ANOVA) 방식에 대한 검정 통계량
- 분산감소량 : 예측오차를 최소화하는 것과 동일한 기준으로,
- 분산의 감소량을 최대화하는 기준의 최적분리에 의해 자식 마디가 형성.
#지니 지수 ★
- 범주가 두 개일 때 한쪽 범주에 속한 비율(p)이 0.5(두 범주가 각각 반반씩 섞여 있는 경우)일 때 불순도가 최대

#학습의 불안정성
- 작은 변화에 의해 예측 모형이 크게 변하는 경우, 그 학습 방법은 불안정
- 가장 안정적인 방법: K-최근접이웃, 선형회귀 모형
- 가장 불안정한 방법: 의사결정 나무
#앙상블 모형의 특징 ★
- 분리 분석의 과적합을 줄이기 위해 개발된 방법
- 여러 개의 훈련용 데이터를 만들고, 훈련용 데이터마다 하나의 분류기를 만드는 방법 ★
- 여러 모형의 결과를 결합함으로써 신뢰성 높은 예측값을 얻을 수 있다. ★
- 각 모형의 상호 연관성이 높을수록 정확도가 감소한다. ★
- 모형의 투명성이 떨어져 원인 분석에는 적합하지 않다. ★
- 이상값에 대한 대응력이 높아진다. ★
- 전체적인 예측값의 분산을 감소시켜 정확도를 높일 수 있다. ★
- 훈련을 한 뒤 예측을 하는데 사용하므로 교사학습법(Supervised learning)이다. ★
- 앙상블은 배깅, 부스팅, 랜덤포레스트를 포함한다.★
#배깅(bagging) ★☆
- 데이터에서 여러 개의 붓스트랩 데이터를 생성해서 각 붓스트랩 데이터 분석 모델에 결합한 후에 최종 예측 모델을 산출하는 것 ★
- 데이터 간의 거리를 측정하여 군집화한다. ★
- 원 데이터 집합으로부터 크기가 같은 표본을 여러 단순 임의 복원 추출하여 각 표본에 대해 분류기를 생성한 후 그 결과를 앙상블하는 방법 ★
- 트랜잭션 사이에 빈번하게 발행하는 규칙을 찾아낸다.★
- 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬하여 지도의 형태로 형상화한다. ★
- 붓스트랩(bootstrap): 주어진 자료에서 동일한 크기의 표본을 랜덤복원추출로 뽑은 자료 ☆
- 보팅(Voting): 여러 개의 모형으로부터 산출된 결과를 다수결에 의해 최종 결과를 선정하는 과정
- 가지치기를 하지 않고 최대한 성장한 의사결정 나무들 사용
- 평균예측 모형을 못 구함 (훈련 자료의 모집단의 분포 모름)
- 훈련자료를 모집단으로 생각하고 평균예측모형을 구한 것과 같음 (분산을 줄이고 예측력 향상)
- 반복추출 방법으로 동일한 데이터가 여러 번 추출될 수도 있고, 어떤 데이터는 한 번도 추출되지 않을 수 있다.
#부스팅(boosting) ☆
- 예측력이 약한 모형들을 결합하여 강한 예측 모형을 만드는 방법 ★
- 훈련오차를 빠르고 쉽게 줄임
- 성능이 배깅보다 뛰어난 경우가 많음
- 배깅과 유사하나 붓스트랩 표본을 구성하는 재표본 과정에서 각 자료에 동일한 확률을 부여하지 않고, 분류가 잘못된 데이터에 더 큰 가중을 두어 표본을 추출 ★
- 붓스트랩 표본을 추출 → 분류기 생성 → 각 데이터의 확률 조정 → ···반복···
#랜덤포레스트(random forest) ★☆
- 의사결정나무을 앙상블하는 방법 중 전체 변수 집합에서 부분 변수 집합을 선택하여 각각의 데이터 집합에 대해 모형을 생성한 후 결합하는 방식 ★
- 의사결정나무모형의 특징인 분산이 크다는 점을 고려하여 배깅과 부스팅보다 더 많은 무작위성을 추가한 방법으로 약한 학습기들을 생성하고 이를 선형결합하여 최종학습기를 만든다.★
- 배깅에 랜덤 과정을 추가한 방법
- 붓스트랩 샘플을 추출하고 트리를 만들어가는 과정은 배깅과 유사
- 예측변수들을 임의로 추출하고, 추출된 변수 내에서 최적의 분할을 만들어나감
- 변수 제거 없이 실행되어 정확도가 좋음
- 해석이 어렵지만 예측력이 높음 (입력 변수가 많을구록 배깅, 부스팅보다 좋음)
- 별도의 검증용 데이터를 사용하지 않더라도, 붓스트랩 샘플과정에서 제외된 자료를 통해 검증을 실시할 수 있다.
예) 보험가입 채널, 상품 종류 등의 정보를 사용하여 자사 고객의 보험 갱신 여부를 예측★☆
#모형 평가 절차 1. 훈련용 자료와 검증용 자료 추출
- 훈련용 자료는 모형 구축용도, 검증용 자료는 모형 검증 용도
- 주어진 데이터에서만 성과를 보이는 과적합화를 해결하기 위한 단계
- 잘못된 가설을 가정하게 되는 2종 오류를 방지 ★
(1) 홀드아웃(hold-out) ★☆
- 랜덤 추출 방식
- 주어진 원천 데이터를 랜덤하게 두 분류로 분리하여 교차 검정을 실시하는 방법
- 하나는 모형학습 및 구축을 위한 훈련용 자료, 하나는 성과평가를 위한 검증용 자료 ★☆
- 훈련용 자료(실험 데이터):검증용 자료(평가 데이터) = 7:3
(2) 교차검증(cross-validation)
- 데이터를 k개로 나누어 k번 반복측정하고, 그 결과를 평균 내어 최종 평가로 사용
- 일반적으로 10-fold 교차 검증이 사용됨
(3) 붓스트랩(bootstrap) ★ ☆
- 교차검증과 유사하게 평가를 반복하지만, 훈련용 자료를 반복 재선정한다는 점에서 다름
- 관측치를 한번 이상 훈련용 자료로 사용하는 복원 추출법에 기반 ★
- 전체 데이터의 양이 크지 않은 경우의 모형 평가에 가장 적합
#모형 평가 절차 2. 모형 학습 및 성능 평가
- 훈련용 자료로 모형을 학습한 뒤, 검증용 자료를 사용해 모형의 분류 및 예측 정확도 평가
- 분류 모형 평가에 사용되는 방법
- 오분류표, ROC 그래프 등
#오분류표(confusion matrix) ★☆
| Predicted | ||
Positive | Negative | ||
Actual | Positive | True Positive | False Negative |
Nagative | False Positive | True Negative | |
정분류율(Accuracy) | - 전체 관측치 중 실제값과 예측치가 일치한 정도 |
오분류율(Error rate) | - 모형이 제대로 예측하지 못한 관측치 (= 1-정분류율) |
재현율(Recall) ★ 민감도(Sensitivity) ★ | - 실제 True인 관측치 중 예측치가 적중한 정도 - 모형의 완전성을 평가하는 지표 |
특이도(Specificity) ★ | - True로 예측한 관측치 중 실제 값이 True인 정도 |
정확도(정밀도, Precison) | - True로 예측한 관측치 중 실제 값이 True인 정도 |
F1지표 ★ | - 재현율과 정확도의 조화평균 |
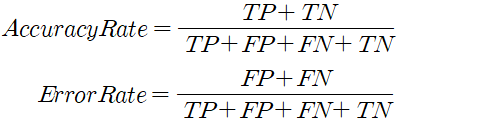
#F점수 ★
- 정확도와 재현율의 가중조화평균(weight harmonic average)을 F점수(F-score)라고 한다.
- 정확도에 주어지는 가중치를 베타(beta)라고 한다.
- 베타가 1인 경우를 특별히 F1점수라고 한다. ★
- 베타가 2인 경우, 재현율에 2배만큼의 가중치를 부여하여 조화평균을 하는 것이다. ★
#범주불균형의 문제 ★
- 분류 모형을 구성하는 경우 예측 실패의 비용이 큰 분류 분석의 대상에 대한 관측치가 현저히 부족하여 모형이 제대로 학습되지 않는 문제
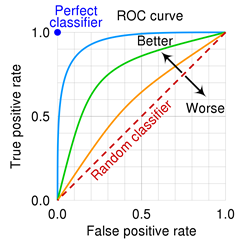
#ROC 그래프 ★☆
- 민감도와 특이도를 사용해서 모델의 성능을 평가
- X축에는 FP Ratio(1-특이도), Y축에는 민감도를 나타냄
- ROC 그래프의 밑부분 면적(AUC)이 넓을 수록 좋은 모형으로 평가
- ROC 그래프에서 이상적으로 완벽히 분류한 모형의 x축과 y축 값 = (0,1) ★☆
 (Roc_curve, Wikipedia)
(Roc_curve, Wikipedia)
#이익도표 ★☆
- 이익(gain) : 목표 번주에 속하는 개체들이 각 등급을 얼마나 분포하고 있는지 나타내는 값
- 이익도표 : 분류된 관측치가 각 등급별로 얼마나 포함되는지 나타내는 도표
- 이익도표(Lift)를 작성함에 있어 평가도구 중 %Captured Reponse를 표현한 계산식 ★
: 해당 집단에서 목표변수의 특정범주 빈도 / 전체 목표변수의 특정범주 빈도 x 100
#향상도 곡선(lift curve) ★☆
- 랜덤모델과 비교하여 해당 모델의 성과가 얼마나 향상되었을지 등급별로 파악하는 그래프
- 상위등급에서 매우 크고 하위 등급으로 갈수록 감소하게 되면 일반적으로 모형의 예측력이 적절하다고 판단하게 된다.
#계층적 군집 정의 및 특징
- 가장 유사한 개체를 묶어 나가는 과정을 반복 하여 원하는 개수의 군집을 형성하는 방법
(n개의 군집으로 시작해 점차 군집의 개수를 줄어나가는 방법 ★)
#군집 간 거리 측정 방법 (연결법)
1) 최단연결법 (단일연결법) ★☆
2) 최장연결법 (완전연결법)
3) 중심연결법
- 군집이 결합될 때, 새로운 군집의 평균은 가중평균을 통해 구해진다.
4) 평균연결법
5) 와드연결법 (Ward Linkage) ★☆
- 크기가 비슷한 군집끼리 병합하게 되는 경향이 있다.
- 군집이 병합되면 오차제곱합은 증가하는데, 증가량이 가장 작아지도록 군집을 형성한다.
- 계층적 군집분석 수행 시 두 군집을 병합하는 방법 가운데 병합된 군집의 오차제곱합이 병합 이전 군집의 오차제곱합에 비해 증가한 정도가 작아지도록 군집형성★
#유클리드(유클리디안, Euclidean) 거리 ★
- 데이터 간 유사성 측정을 위해 사용, 통계적 개념이 내포X, 변수들의 산포정도 감안X
- 두 점을 잇는 가장 짧은 직선거리 ★
- 공통으로 점수를 매긴 항목의 거리를 통해 판단하는 측도이다. ★

#맨하탄(Manhattan) 거리
- 유클리드와 함께 가장 많이 쓰는 거리, 건물간 최단거리 계산 ★

#표준화 (Statistical) 거리
- 해당 변수의 표준편차로 척도 변환 후 유클리디안 거리를 계산★
- 표준화를 하게 되면 척도의 차이, 분산의 차이로 인해 왜곡을 피할 수 있다. ★

#마할라노비스 거리
- 통계적 개념이 포함된 거리, 변수들의 산포를 고려하여 표준화한 거리 ★
- 변수의 표준화와 상관성을 동시에 고려한 통계적 거리 ★
- 두 벡터 사이의 거리를 산포를 의미하는 표본 공분산으로 나눠주어야 하며 그룹에 대한 사전 지식 없이는 표본 공분산을 계산할 수 없으므로 사용하기 어렵다. ★

#자카드 거리 ★
- Boolean 속성으로 이루어진 두 객체 간의 유사도 측정에 사용한다.
#민코우스키(Minkowski) 거리 ★
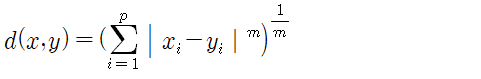
#캔버라 거리

#체비셰프 거리 (체스보드 거리, 최고 거리)
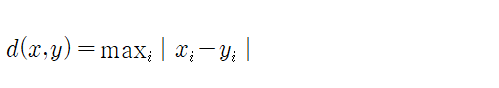
#군집 간 거리 (연속형, 범주형 변수)
- 연속형 변수 : 유클리디안 거리, 표준화 거리, 마할노비스거리, 체비셰프 거리, 맨하탄 거리, 캔버라 거리, 민코우스키 거리 ⇒ dist 함수 지원 ★
- 범주형 변수 : 카드 거리, 자카드 계수, 코사인 거리, 코사인 유사도
#군집 간 거리 (수학적, 통계적 거리)
1) 수학적 거리: 유클리드 거리, 맨하튼 거리, 민코우스키 거리
2) 통계적 거리: 표준화 거리, 마할라노비스 거리
#비계층적 군집방법의 장점과 단점
비계층적 군집화의 장점 | 비계층적 군집화의 단점 |
- 주어진 데이터의 내부구조에 대한 사전정보 없이 의미있는 자료구조를 찾을 수 있다. - 다양한 형태의 데이터에 적용이 가능하다. - 분석방법 적용이 용이하다. | - 가중치와 거리정의가 어렵다. - 초기 군집수를 결정하기 어렵다. - 사전에 주어진 목적이 없으므로 결과 해석이 어렵다. |
#K-means Clustering 과정 ★
- 원하는 군집의 갯수(K)와 초기 값(seed)들을 정해 seed 중심으로 군집을 형성 ★
- 각 데이터를 거리가 가장 가까운 seed가 있는 군집으로 분류 ★
- 각 군집의 seed값을 다시 계산
- 모든 개체가 군집으로 할당될 때까지 위와 같은 과정 계속 반복
#K-평균 군집 분석의 장점과 단점
K-means Clustering의 장점 | K-means Clustering의 단점 ★ |
- 알고리즘이 단순하며, 빠르게 수행되어 분석 방법 적용이 용이 - 계층적 군집분석에 비해 많은 양의 데이터를 다룰 수 있음 | - 군집의 수, 가중치와 거리 정의가 어려움 - seed값에 따라 결과가 달라질 수 있음 (항상 일정한 결과 X) - 볼록한 형태가 아닌(non-convex) 군집이 (예 : U형태의 군집) 존재할 경우에는 성능이 떨어짐★ |
#PAM(partitioning around medoids) ★
- 이상값(Outlier)에 민감하여 군집 경계의 설정이 어렵다는 단점을 극복하기 위해 등장한 비계층적 군집 방법
- 이상치에 대하여 강건한(robust) 군집분석 방법
- K-Medois 군집을 이용한 대표적인 알고리즘
#min-max 정규화 ★
- 정규화 방법 중 원(raw) 데이터의 분포를 유지하면서 정규화가 가능한 방법
#혼합 분포 의 정의 및 특징
- 데이터가 k개의 모수적 모형(정규분포 혹은 다변량 분포를 가정)의 가중합으로 표현되는 모집단 모형으로 부터 나왔다는 가정하에서, 모수와 함께 가중치를 자료로부터 추정하는 방법
- 데이터가 k개의 모수적 모형(군집)의 가중합으로부터 나왔다는 가정
- 각 데이터는 k개의 추정된 모형 중 어느 모형에 속할 확률이 높은지에 따라 분류
- k개의 각 모형은 군집을 의미하여, 각 데이터는 추정된 k개의 모형 중 어느 모형으로부터 나왔을 확률이 높은지에 따라 군집의 분포가 이뤄짐
#K-means vs 혼합분포군집
- 두 방법 모두 1개의 클러스터로 출발
- k-mean은 클러스터를 중심거리로, EM은 MSL로 거리측정
- 클러스터를 늘리면 이전보다 클러스터 중심에서 평균 거리는 짧아지고 EM은 우도가 커짐
- 혼합분포군집은 확률분포를 도임하여 군집을 수행하는 점이 다름
- EM알고리즘을 이용한 모수 추정에서 데이터가 커지면 수렴하는데 시간이 오래 걸리고, 군집의 크기가 작으면 추정의 정도가 떨어짐
- k-mean 평균과 같이 이상값에 민감하다.
#EM(Expectation Maximizaion) 알고리즘의 진행 과정 ★
E-단계 | 잠재변수 Z의 기대치 계산 |
M-단계 | 잠재변수 Z의 기대치를 이용하여 파라미터 추정 |
- E단계: 각 자료에 대해 Z의 조건부분포(어느 집단에 속할지에 대한)로부터 조건부 기댓값을 구할 수 있음
- M단계: 관측변수 X와 잠재변수 Z를 포함하는 (X, Z)에 대한 로그-가능도함수(이를 보정된(augmented) 로그-가능도함수라 함)에 Z 대신 상수 값인 Z의 조건부 기댓값을 대입하면, 로그-가능도함수를 최대로 하는 모수를 쉽게 찾을 수 있다.
- 갱신된 모수 추정치에 대해 위 과정을 반복한다면 수렴하는 값을 얻게 되고, 이는 최대 가능도 추정치로 사용될 수 있다.
#SOM
- 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬화하여 지도의 형태로 형성화하는 클러스터링 방법 ★
- 차원축소와 군집화를 동시에 수행하는 기법이다. ★
- 대표적인 비지도학습이다. ★
- 비지도 신경망으로 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬해 지도의 형태로 형상화하는 것으로 입력 변수의 위치 관계를 그대로 보존한다는 특징이 있다. ★
- 시각적인 이해가 쉽고, 실제 데이터가 유사하면 지도상에서 가깝게 표현돼 패턴 발견, 이미지 분석 등에서 뛰어난 성능을 보인다.
- SOM 알고리즘은 고차원의 데이터를 저차원의 지도 형태로 형상화하기 때문에 시각적으로 이해하기 쉬울 뿐 아니라 변수의 위치 관계를 그대로 보존하기 때문에 실제 데이터가 유사하면 지도상 가깝게 표현된다. ★
- SOM은 경쟁 학습으로 각각의 뉴런이 입력벡터와 얼마나 가까운가를 계산하여 연결강도를 반복적으로 재조정하여 학습한다.
- 단계를 반복하면서 연결 강도는 입력 패턴과 가장 유사한 경쟁층 뉴런이 승자가 됨 ★
- 승자 독식 구조로 인해 경쟁층에서는 승자 뉴런만이 나타남 ★
#SOM의 경쟁층 ★
- 입력 벡터와 경쟁층 노드간의 유클리드 거리를 계산, 입력 벡터와 가장 짧은 노드를 선택
- 입력 벡터의 특성에 따라 입력 벡터가 한 점으로 클러스터링되는 층
#신경망 모형 VS SOM
신경망 모형 | SOM |
- 연속적인 층으로 구성 - 에러 수정을 학습 | - 2차원의 그리드로 구성 |
#군집 타당성 지표에서 고려사항
- 군집 간 거리 : 군집 간 거리는 멀수록 좋음
- 군집의 지름
- 군집의 분산 : 군집 내 분산은 작을수록 좋음
#실루엣 계수(Silhouette Index) ★☆
- 군집의 품질을 정량적으로 계산해주는 방법
- 한 군집 내 데이터들이 다른 군집과 비교할 때 얼마나 비슷한지를 나타낸다.
- 군집의 밀도정도를 계산하는 방법으로 군집 내의 거리와 군집 간의 거리를 기준으로 군집 분할의 성과를 평가하는 것
#연관규칙의 개념
- 항목들간의 조건-결과 식으로 표현되는 유용한 패턴 ★
- 상품의 구매, 서비스 등 일련의 거래·사건들 간의 규칙을 발견하기 위해 적용.
#연관규칙의 장단점
연관규칙의 장점 | 연관규칙의 단점 |
- 조건반응으로 표현되는 연관분석의 결과를 이해하기 쉬움 - 강력한 비목적성 분석기법 | - 분석 품목의 수가 증가하면 분석 계산이 기하급수적으로 증가 |
#연관분석의 측도 3가지 ★
(1) 지지도
- 전체 거래 중 항목 A, B를 동시에 포함하는 거래의 비율
(2) 신뢰도
- 항목 A를 포함한 거래 중에서 항목 A, B가 같이 포함될 확률
(3) 향상도 ★
- 도출된 규칙의 우수성을 평가하는 기준으로 두 품목의 상관관계를 기준으로 도출된 규칙의 예측력을 평가하는 지표
- A가 주어지지 않았을 때 품목 B의 확률에 비해, A가 주어졌을 때 품목 B의 확률의 증가율
- A와 B 사이에 아무런 상호관계가 없으면 향상도는 1 ★
- 향상도가 1보다 높을수록 연관성이 높다. ★
- 향상도가 1보다 클 경우에는 양(+)의 상관관계가 있다.
- 향상도가 1보다 크면 해당 규칙은 결과를 예측하는 데 있어 우수하다. ★
댓글
댓글 쓰기